2. Views - Virtuelle Tabellen in SQL
Views - Virtuelle Tabellen in SQL - Teil 2
Abschnitt betitelt „Views - Virtuelle Tabellen in SQL - Teil 2“In Teil 1 haben wir die Grundlagen von Views in SQL kennengelernt: Was sind Views, welche Vorteile bieten sie, und wie werden sie definiert und genutzt. In diesem zweiten Teil gehen wir tiefer ins Detail und betrachten fortgeschrittene Konzepte, Best Practices und Besonderheiten verschiedener Datenbanksysteme.
Was sind Views überhaupt?
Abschnitt betitelt „Was sind Views überhaupt?“Wiederholung: Eine View ist eine benannte, gespeicherte SQL-Abfrage, die sich nach außen wie eine Tabelle verhält, aber nicht zwingend eigene Daten speichert. Man kann sie wie eine Tabelle selektieren (SELECT ... FROM view_name), und - je nach System und Aufbau - teilweise auch ändern (INSERT/UPDATE/DELETE), wobei die Änderungen an die zugrunde liegenden Basistabellen durchgereicht werden. Views dienen in erster Linie der Abstraktion, Kapselung und Sicherheit.
Wichtig ist die Trennung:
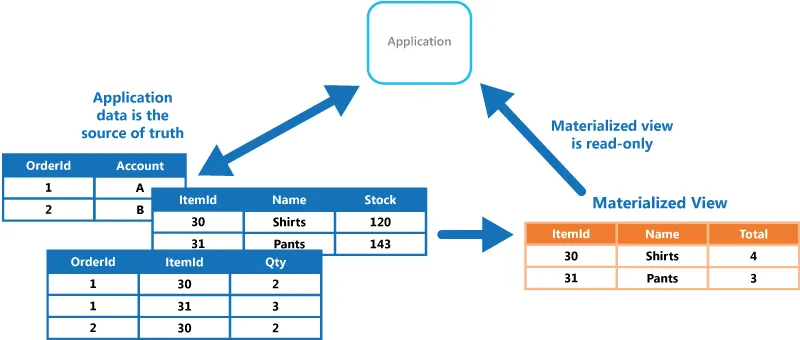
- Normale (logische) View: speichert keine Daten, sondern nur eine Definition (die Query). Jede Abfrage gegen die View wird vom Optimizer in eine Abfrage auf die Basistabellen “umgeschrieben” (Query Rewriting).
- Neu Materialisierte View: speichert das Ergebnis der zugrunde liegenden Abfrage persistent. Sie muss manuell (oder zeitgesteuert) aktualisiert werden. Dafür liefert sie oft deutlich bessere Performance für teure Aggregationen/Joins.
Wofür kann man Views gebrauchen?
Abschnitt betitelt „Wofür kann man Views gebrauchen?“-
Abstraktionsschicht & API für Daten
- Views stellen eine “vertragliche” Schnittstelle dar. Anwendungen sprechen die View an, während sich die interne Tabellenstruktur ändern darf (Migrationen, Normalisierung), solange die View weiterhin das gleiche Schema liefert.
-
Sicherheitsbarriere
- Man kann feingranular SELECT-Rechte auf Views geben, ohne Zugriff auf die Basistabellen zu gewähren. So lassen sich Spalten ausblenden (z. B.
password_hash) oder Zeilen filtern (z. B.WHERE student.clazz IN ("4AHITM", "4BHITM")).
- Man kann feingranular SELECT-Rechte auf Views geben, ohne Zugriff auf die Basistabellen zu gewähren. So lassen sich Spalten ausblenden (z. B.
-
Wiederverwendbare komplexe Logik
- Häufig benötigte Joins, CASE-Ausdrücke, Window-Funktionen etc. einmal definieren, überall nutzen. Das reduziert Duplikate im Code und das Risiko von Inkonsistenzen.
-
Berichte & Analytics
- Für BI/Reporting sind Views ideal, um den Datenkonsumenten ein stabiles, gut dokumentiertes Datenmodell zu geben - oft in Kombination mit materialisierten Views für Performance.
-
Migrationen & Refaktorierung
- Wenn Spalten oder Tabellen umbenannt/aufgesplittet werden, kann eine View den alten Zustand simulieren, um Legacy-Applikationen übergangsweise weiter zu versorgen.
Grundlegende Syntax
Abschnitt betitelt „Grundlegende Syntax“-- Einfache ViewCREATE VIEW reporting.orders_summary ASSELECT c.id AS customer_id, c.name, COUNT(o.id) AS order_count, SUM(o.total_amount) AS total_amountFROM customers cLEFT JOIN orders o ON o.customer_id = c.idGROUP BY c.id, c.name;
-- Aktualisierbare (auto-updatable) View - einfaches Mapping auf eine BasistabelleCREATE VIEW app.users_public ASSELECT id, email, display_nameFROM app.usersWHERE is_deleted = falseWITH LOCAL CHECK OPTION;
-- Materialisierte ViewCREATE MATERIALIZED VIEW analytics.mv_daily_sales ASSELECT date_trunc('day', created_at) AS day, SUM(total_amount) AS revenueFROM ordersGROUP BY 1WITH NO DATA;Wichtige DDL-Operationen:
CREATE OR REPLACE VIEWpasst die Definition an, ohne Grants zu verlieren (Achtung bei Spalten-Layout).ALTER VIEW ... RENAME/OWNER/SET SCHEMAetc. für Verwaltung.DROP VIEWentfernt die View (ggf.DROP VIEW ... CASCADE, wenn abhängige Objekte existieren).- Materialisierte Views:
REFRESH MATERIALIZED VIEW(optionalCONCURRENTLY).
Updatability von Views (PostgreSQL)
Abschnitt betitelt „Updatability von Views (PostgreSQL)“PostgreSQL macht schlichte Views über eine einzelne Basistabelle oft automatisch aktualisierbar (INSERT/UPDATE/DELETE), wenn bestimmte Bedingungen erfüllt sind:
- Keine Aggregation,
DISTINCT,GROUP BY,HAVING,UNION/EXCEPT/INTERSECT,WINDOW FUNCTIONSetc. - Keine schreibhemmenden Konstrukte wie bestimmte Funktionen/Joins, die nicht eindeutig auf eine Zielzeile abbildbar sind oder Subqueries, es sei denn diese sind eindeutig.
- Kein “verstecktes” Mapping über mehrere Tabellen.
Wenn eine View nicht automatisch updatable ist, gibt INSTEAD OF-Trigger auf der View: Man definiert, was bei INSERT/UPDATE/DELETE passieren soll, und leitet die Operationen selbst in die Basistabellen.
CHECK OPTION in PostgreSQL:
WITH [LOCAL|CASCADED] CHECK OPTIONbei CREATE VIEW verhindert, dass über die View Änderungen erfolgen, die die Zeile “aus dem Sichtbereich” der View herausfallen lassen. Beispiel: Eine View filtertWHERE is_deleted = false. Mit CHECK OPTION kann man eine Zeile nicht aufis_deleted = truesetzen, solange man über diese View schreibt.
Sicherheit
Abschnitt betitelt „Sicherheit“- Rechteprüfung: Um eine View zu nutzen, braucht der Benutzer SELECT auf die View; er benötigt keine Rechte auf die Basistabellen.
- Row-Level-Security (RLS): RLS gilt auf den Basistabellen. Wichtig ist zu verstehen, mit wessen Identität RLS geprüft wird (Owner vs. invoker-Kontext). In PostgreSQL greifen RLS-Policies grundsätzlich gegen den aktuellen Benutzer; wenn man mit Views Sicherheitsgrenzen bauen will, musst man die Interaktion von RLS, View-Grants und ggf.
SET ROLEsauber durchdenken.
Performance-Aspekte
Abschnitt betitelt „Performance-Aspekte“Normale Views:
- Sie sind syntaktischer Zucker; die Abfrage wird in die Basistabellen aufgelöst. Performance entspricht in etwa der “entpackten” Query.
- Nesting: Viele geschachtelte Views (also Views welche wieder auf Views zugreifen) können zu komplexen, schwer zu optimierenden Plänen führen. Der Planner in PostgreSQL ist gut, aber sehr tiefe Nestings mit vielen CTEs/Window-Funktionen/Joins können die Komplexität hochtreiben.
SELECT *vermeiden: Ändert sich die Spaltenliste der Basistabellen, können sich Views “unsichtbar” verändern oder brechen (“column drift”). Außerdem zwingtSELECT *den Planner evtl. zu mehr Arbeit, als nötig.
Materialisierte Views:
-
Sie speichern Ergebnisse persistent. Ideal für teure Aggregationen, Dimensionen, rollup-artige Sichten.
-
Refresh:
REFRESH MATERIALIZED VIEW mv;blockiert Leser kurz, während neu befüllt wird.REFRESH MATERIALIZED VIEW CONCURRENTLY mv;ermöglicht gleichzeitiges Lesen während des Refreshs, erfordert aber eine eindeutige, nicht-NULL-Schlüsselspalte bzw. Unique Index auf der materialisierten View. Außerdem darf das nicht in einem expliziten Transaktionsblock laufen.WITH NO DATAbeim Anlegen spart initiale Ladezeit; späterREFRESHausführen.
-
Indexierung: Man kann Indizes auf materialisierten Views anlegen.
-
Keine automatische Aktualisierung: Man muss Jobs planen (Cron,
pg_cron,systemdTimer, CI/CD-Task, Background Worker), Trigger-basierte Inkremtalität selbst bauen oder externe Tools einsetzen, welche denREFRESHausführen.
Do’s & Don’ts
Abschnitt betitelt „Do’s & Don’ts“- Schema qualifizieren:
CREATE VIEW reporting.sales AS SELECT ... FROM public.orders .... - Eindeutige Spaltensätze definieren (keine
SELECT *) und View-Schnittstellen wie eine API versionieren (z. B.v1_,v2_). - CHECK OPTION für schreibbare Views, um Datenkonsistenz sicherzustellen.
- Materialisierte Views indexieren und
REFRESH ... CONCURRENTLYeinplanen, wenn Verfügbarkeit wichtig ist. - Abhängigkeiten im Blick behalten: Bei Spalten-Renames/Type-Changes bricht die View (ggf. erst zur Laufzeit). Automatisierte Tests/CI können das früh entdecken.
- EXPLAIN (ANALYZE, BUFFERS) (siehe Performance später) nutzen, um Performance von View-gestützten Abfragen zu prüfen. Gegebenenfalls die View-Definition “entpacken” und gezielt optimieren (Indizes auf Basistabellen, Statistiken, Partitionspruning).
- ORDER BY in Views für Sortierung als gegeben oder garantiert betrachten: Das ist nicht garantiert - Sortierung gehört in die aufrufende Abfrage. (In materialisierten Views kann die physische Ordnung anders sein; verlasse dich nie auf implizite Sortierung.)
- Tief verschachteln: Vermeide pyramidenartige “View-auf-View-auf-View”-Konstrukte. Besser: zentrale, klar dokumentierte Basissichten bauen.
- Sicherheitslogik im App-Code allein: Leake keine sensiblen Spalten in Views, die breit freigegeben werden. Nutze Views aktiv zur Least-Privilege-Durchsetzung. Gib nur die Spalten frei, die wirklich benötigt werden; keine einzige mehr.
- Refresh-Plan vergessen: Materialisierte Views ohne Maintenance-Plan sind Tick-Bomben - Daten veralten, Analysen werden inkonsistent. Die Daten sind von … wann genau? Wie alt diese Tabelle?
Arten von Views und ihre Vor- & Nachteile
Abschnitt betitelt „Arten von Views und ihre Vor- & Nachteile“Normale (logische) Views
Abschnitt betitelt „Normale (logische) Views“Vorteile
- Immer aktuell, da Abfrage on-the-fly ausgeführt wird.
- Keine Speicher-Overheads für Ergebnisdaten.
- Einfach zu pflegen;
CREATE OR REPLACE VIEWgenügt.
Nachteile
- Performance entspricht der zugrunde liegenden (evtl. teuren) Query.
- Keine automatische Persistierung teurer Zwischenergebnisse.
Typische Einsätze
- Sicherheitsfilter, Spaltenmaskierung, API-Layer, leichte Denormalisierung.
Materialisierte Views (PostgreSQL)
Abschnitt betitelt „Materialisierte Views (PostgreSQL)“Vorteile
- Sehr schnelle Abfragen auf rechenintensiven Sichten.
- Indexierbar,
REFRESH ... CONCURRENTLYfür hohe Verfügbarkeit.
Nachteile
- Müssen aktiv aktualisiert werden; Staleness-Risiko.
- “Echtzeit” nur mit aufwändigen inkrementellen Ansätzen.
CONCURRENTLYerfordert Unique-Index und spezielle Rahmenbedingungen.
Typische Einsätze
- Reporting-Dashboards, Tages-Aggregationen, dimensionale Sichten, teure Joins.
Partitionierte/union-basierte Sichten (DB-spezifisch)
Abschnitt betitelt „Partitionierte/union-basierte Sichten (DB-spezifisch)“- In PostgreSQL kann man UNION-Views über partitionierte Tabellen bauen.
CREATE VIEW reporting.sales_all ASSELECT id, created_at, amount FROM sales_2025UNION ALLSELECT id, created_at, amount FROM sales_2024UNION ALLSELECT id, created_at, amount FROM sales_2023;Partitionierte Tabellen sind Tabellen, mit dem man eine logisch einzige Tabelle in mehrere physische Teil-Tabellen (Partitionen) aufteilt, z.B. nach Datum (Jahr), Region, Schuljahr etc. Das verbessert Performance und Wartbarkeit bei großen Datenmengen.
UNION ALL hängt die Zeilen einfach aneinander (keine Dublettenentfernung).
Unterschiede zwischen PostgreSQL und anderen Systemen
Abschnitt betitelt „Unterschiede zwischen PostgreSQL und anderen Systemen“PostgreSQL vs. MariaDB/MySQL
Abschnitt betitelt „PostgreSQL vs. MariaDB/MySQL“Materialisierte Views
- PostgreSQL: Native materialisierte Views mit
CREATE MATERIALIZED VIEW,REFRESH MATERIALIZED VIEW [CONCURRENTLY], Indexierung möglich. - MySQL/MariaDB: Keine nativen materialisierten Views. Man simuliert sie mit Tabellen + Triggern/Events (oder Schedulern), oder nutzt externe Tools. MariaDB bietet zwar teils komfortablere Event Scheduler-Optionen, aber dennoch bleibt es eine Eigenbaulösung.
Updatability & CHECK OPTION
- Beide unterstützen updatable Views unter bestimmten Bedingungen sowie
WITH CHECK OPTION.
Query Rewrite Richtung MVs
- PostgreSQL: kein automatisches Rewrite “Query → MV”. Du musst die MV direkt ansprechen oder Views über die MV bauen.
- MySQL/MariaDB: Nicht vorhanden, da keine nativen MVs.
Praxis-Takeaway:
Wenn in MySQL/MariaDB wiederkehrende, teure Aggregationen gebraucht werden, dann sind eigene Tabellen + Refresh-Logik einzuplanen (Events/Triggers). In PostgreSQL kann man die gleiche Aufgabe mit materialisierten Views + Indexen + REFRESH CONCURRENTLY eleganter lösen.
PostgreSQL vs. SQLite
Abschnitt betitelt „PostgreSQL vs. SQLite“Funktionsumfang
-
SQLite ist minimalistisch:
- Views: ja, aber immer read-only, es sei denn, man definiert
INSTEAD OF-Trigger auf der View. - Materialisierte Views: Nein. Man simuliert wie in MySQL durch Tabellen.
- Rechte: Kaum ein Rechte-/Rollenmodell im DB-Kern - Sicherheitsebene liegt eher in der Anwendung.
- Views: ja, aber immer read-only, es sei denn, man definiert
Praxis-Takeaway:
SQLite-Views dienen primär der Abstraktion. Für Performance-Caching baut man Tabellen + Trigger/Jobs. Sicherheitskonzepte wie in PostgreSQL (Grants auf Views statt Basistabellen) gibt es so nicht - das liegt in der App-Logik.
Konkrete Best Practices (PostgreSQL)
Abschnitt betitelt „Konkrete Best Practices (PostgreSQL)“-
Sicht als API behandeln
- Namenskonventionen (
app_public.,reporting.,analytics.). - Nie
SELECT *, sondern Spalten explizit - stabilisiert das Interface.
- Namenskonventionen (
-
Sicherheit korrekt schneiden
- Nur SELECT-Grants auf die View, keine Grants auf Basistabellen.
-
Materialisierte Views bewusst betreiben
-
Refresh-Strategie pro MV:
- “Stale-Budget” (wie alt dürfen Daten sein?),
- “Refresh-Fenster” (nachts, alle 5min, stündlich?),
CONCURRENTLYfalls 24/7-Verfügbarkeit nötig.
-
Unique-Index für
CONCURRENTLY. Beispiel:CREATE UNIQUE INDEX ON analytics.mv_daily_sales (day);REFRESH MATERIALIZED VIEW CONCURRENTLY analytics.mv_daily_sales; -
Abhängigkeiten prüfen: Wenn MV auf andere Views/MVs aufsetzt (z.B. MV1 → MV2 → View), plane die Refresh-Reihenfolge (M2 vor M1).
-
-
Updatable Views prüfen
- Für CRUD-ähnliche Sichten zuerst versuchen, die View so einfach zu halten, dass sie auto-updatable ist.
- Falls komplexer:
INSTEAD OF-Trigger undCHECK OPTION.
-
Performance messen, nicht raten
EXPLAIN (ANALYZE, BUFFERS)(siehe Performance) der entpackten Query, nicht nur der View.- Indizes auf Basistabellen (oder MV) ableiten aus den häufigsten Prädikaten/Joins.
- Bei vielschichtigen Views ggf. CTEs oder Zwischen-MVs einziehen, um Planner-Komplexität zu verringern.
-
Deployment/CI
- Migrationsskripte (z. B. mit
ALTER VIEW,CREATE OR REPLACE VIEW) testen. - Breaking Changes vermeiden: zuerst neue View-Version bereitstellen, Konsumenten umstellen, erst dann die alte entfernen.
- Migrationsskripte (z. B. mit
Typische Fehlerbilder
Abschnitt betitelt „Typische Fehlerbilder“-
“Meine View ist plötzlich langsam!”
Ursache: Basistabellen gewachsen, Statistiken alt, Planner trifft ungünstige Entscheidungen, zu viele verschachtelte Sichten. Lösung:
ANALYZE, passende Indizes, View entpacken und gezielt optimieren, evtl. Materialisierung einziehen. -
“
REFRESH MATERIALIZED VIEW CONCURRENTLYmeckert über fehlenden Unique Index!”Ursache: MV hat keinen eindeutigen Index, der jede Zeile eindeutig identifiziert. Lösung: Unique Index anlegen (ggf. künstlicher Schlüssel), dann erneut
REFRESH ... CONCURRENTLY. -
“Upsert/Update über View schlägt fehl.”
Ursache: View nicht (auto)updatable. Lösung: View vereinfachen oder
INSTEAD OF-Trigger implementieren. -
“ORDER BY in View greift nicht.” Ursache: SQL-Standard - äußere Abfrage bestimmt die Sortierung. Lösung:
ORDER BYimmer im finalenSELECTsetzen.