3. Performance
Performance - Optimierung
Abschnitt betitelt „Performance - Optimierung“Die Performance einer relationalen Datenbank entsteht aus dem Zusammenspiel vieler Faktoren – sie ist das Ergebnis einer gut abgestimmten Architektur. Ziel ist immer, den Flaschenhals zwischen CPU, Arbeitsspeicher, I/O und Netzwerk so weit wie möglich zu vermeiden oder abzumildern.
Motivation
Abschnitt betitelt „Motivation“In der täglichen Arbeit zeigt sich, wie stark kleine Änderungen an Datenbankstrukturen oder Konfigurationen wirken können. Wir werden auf alle notwendigen Maßnahmen später gezielt eingehen. Hier vorweg ein paar Beispiele:
- Beispiel 1 – fehlender Index:
Eine Webanwendung lädt eine Kundenliste aus einer Tabelle mit einer Million Datensätzen.
Ohne Index auf der Spalte
nachnamedauert die Abfrage über 10 Sekunden, weil die gesamte Tabelle durchsucht werden muss (full table scan). Nach dem Anlegen eines einfachen B-Tree-Indexes reduziert sich die Laufzeit auf unter 100 Millisekunden – eine 100-fache Beschleunigung. - Beispiel 2 – ineffiziente Abfrage:
Eine Statistik-Abfrage verwendet mehrere verschachtelte Subqueries.
Durch Umwandlung in eine einzige Abfrage mit einem
JOINund einerGROUP BY-Klausel sinkt die Ausführungszeit von 3,8 Sekunden auf 0,4 Sekunden. Gleichzeitig verringert sich die CPU-Last um über 70 %. - Beispiel 3 – falsche Konfiguration:
Ein PostgreSQL-Server nutzt die Standardwerte (
shared_buffers = 128 MB). Nach Anpassung auf 4 GB (bei 16 GB RAM) steigt die Cache-Trefferquote von 75 % auf 98 %, was die Anzahl physischer I/O-Zugriffe um den Faktor 20 reduziert.
Performance-Optimierung ist keine reine „Feinjustierung“ – sie entscheidet oft darüber, ob eine Anwendung flüssig reagiert oder spürbar träge wirkt, insbesondere bei wachsender Datenmenge und Benutzerzahl.
Performance-Tuning bedeutet deshalb nicht, einzelne Parameter zu verändern, sondern die gesamte Datenbankumgebung als integriertes System zu verstehen. Nur wenn Datenmodell, Indexstrategie, Abfragen, Caching, Wartung und Überwachung zusammenwirken, lässt sich langfristig eine stabile und schnelle Datenbankumgebung erreichen.
Grundprinzipien
Abschnitt betitelt „Grundprinzipien“Im Folgenden sind die zentralen Grundprinzipien zusammengefasst, die als Leitlinie jeder Optimierung dienen:
1. Speicherverwaltung
Abschnitt betitelt „1. Speicherverwaltung“Ziel ist es, häufig genutzte Daten im RAM zu halten und gleichzeitig genug Speicher für das Betriebssystem zu lassen. Zu wenig Speicher für die Datenbank führt zu häufigen Festplattenzugriffen; ein zu großer Speicheranteil verdrängt hingegen den Betriebssystem-Cache.
2. Datenmodell und Datentypen
Abschnitt betitelt „2. Datenmodell und Datentypen“Ein klar strukturiertes, logisch konsistentes Schema vermeidet unnötige Joins und doppelte Datenhaltung. Eine saubere Normalisierung ist deshalb Grundvoraussetzung. In Einzelfällen kann gezielt denormalisiert werden (z.B. bei Lese-Hotspots).
Passende Datentypen (z. B. INT statt TEXT) sparen Speicher und beschleunigen Vergleiche. Vermeide z.B. Strings bei Schlüsseln.
Partitionierung hilft, große Tabellen handhabbar zu halten (z.B. zeitbasierte horizontale Partitionierung).
3. Indexstrategie
Abschnitt betitelt „3. Indexstrategie“Gezielt eingesetzte Indizes beschleunigen Such- und Sortieroperationen enorm, dürfen aber Schreibvorgänge nicht übermäßig verlangsamen. Deshalb ist es wichtig, das Datenmodell und die Verwendung der Datenbank gut zu kennen - also welche Abfragen und Datenmanipulationen in welcher Häufigkeit ausgeführt werden.
Eine regelmäßige Analyse und Pflege der Indizes verhindert Fragmentierung und stellt sicher, dass der Query Planner optimale Wege findet.
4. Abfrage-Optimierung
Abschnitt betitelt „4. Abfrage-Optimierung“Die meisten Performanceprobleme entstehen durch ineffiziente SQL-Abfragen. Eine langsame Abfrage multipliziert sich bei jedem Aufruf. Eine effiziente SQL-Struktur spart I/O, CPU und Speicher.
Abfragepläne sollten regelmäßig überprüft werden, um langsame Joins, unnötige Subqueries und Full Table Scans zu vermeiden. Meist stammen 80 % der Last von 20 % der Abfragen.
Prepared Statements und gezielte Filterung erhöhen die Ausführungsgeschwindigkeit deutlich. Auch Materialized Views können helfen.
5. Caching und Connection-Pooling
Abschnitt betitelt „5. Caching und Connection-Pooling“Durch Caching werden häufig benötigte Daten direkt aus dem Arbeitsspeicher bereitgestellt, wodurch Latenzen sinken, denn jede Antwort, die nicht erneut berechnet werden muss, spart Ressourcen. Caching verschiebt die Last von CPU/I/O zu RAM. Hier kann z.B. eine Memory-Datenbank wie z.B. Redis als Cache die relationale Datenbank spürbar entlasten. Ein Cache sollte aber eine hohe Trefferquote haben, sonst bringt er nichts und verursacht nur zusätzlichen Aufwand.
Connection-Pooling reduziert ebenfalls Verbindungsauf- und -abbau und entlastet den Server bei vielen gleichzeitigen Clients.
6. Replikation und Skalierung
Abschnitt betitelt „6. Replikation und Skalierung“Zur Bewältigung besonders hoher Lasten, die ein einziger Datenbank-Server nicht mehr bewältigen kann, werden Daten auf mehrere Server verteilt. Lese- und Schreiboperationen lassen sich trennen (Read/Write-Splitting), Replikation sorgt für Lastverteilung und Ausfallsicherheit. Sharding ermöglicht horizontales Wachstum (horizontale Skalierung, scale out).
7. Wartung und Überwachung
Abschnitt betitelt „7. Wartung und Überwachung“Eine schnelle Datenbank bleibt nur dann schnell, wenn sie gepflegt wird.
Automatische Prozesse wie VACUUM, ANALYZE oder OPTIMIZE TABLE verhindern Datenmüll, halten Statistiken aktuell und sorgen dafür, dass der Optimizer fundierte Entscheidungen trifft.
Monitoring-Tools helfen weiters, Engpässe und Trends frühzeitig zu erkennen.
8. Storage- und Engine-Optimierung
Abschnitt betitelt „8. Storage- und Engine-Optimierung“Effizientes I/O-Management ist entscheidend für Transaktionsgeschwindigkeit. Log-Dateien (WAL/Redo) sollten auf schnellen Datenträgern liegen, Checkpoints nicht zu häufig ausgelöst werden, und Transaktionen möglichst kurz bleiben, um Locking zu vermeiden.
9. Hochverfügbarkeit und Failover
Abschnitt betitelt „9. Hochverfügbarkeit und Failover“Leistungsfähigkeit schließt Verfügbarkeit mit ein: Nur ein ausfallsicheres System kann dauerhaft performant wirken. Automatisches Failover, Clusterbetrieb und Load-Balancing stellen sicher, dass selbst bei Ausfällen keine signifikanten Verzögerungen entstehen.
Index Tuning
Abschnitt betitelt „Index Tuning“Indizes sind ein zentrales Werkzeug zur Performance-Optimierung in relationalen Datenbanken. Sie beschleunigen Datenzugriffe erheblich, indem sie das Durchsuchen, Sortieren und Verbinden von Daten optimieren – insbesondere bei häufigen WHERE-, JOIN-, oder ORDER BY-Klauseln.
Statt jede Zeile einer Tabelle zu prüfen, nutzt die Datenbank eine separate Datenstruktur, um relevante Zeilen schnell zu finden.
Grundprinzip der Index-Funktion
Abschnitt betitelt „Grundprinzip der Index-Funktion“Ein Index funktioniert ähnlich wie das Inhaltsverzeichnis eines Buchs: Er enthält eine geordnete Struktur, mit deren Hilfe gezielt auf Datensätze zugegriffen werden kann, ohne die gesamte Tabelle sequenziell zu durchsuchen.
Beispiel:
SELECT * FROM users WHERE last_name = 'Müller';Ohne Index: Jede Zeile der Tabelle wird geprüft → Full Table Scan dauert z.B. ca. 10 Sekunden bei einer Million Datensätzen. Mit Index: Die Suche erfolgt über eine geordnete Struktur (z. B. B-Baum) → logarithmische Suchzeit reduziert die Suchdauer auf ca. 100ms → 100 mal schneller.
Datenbanken bieten verschiedene Index-Strukturen an (Hash-Funktion, Bitmap, invertierter Index etc.).
Am häufigsten kommt ein B-Tree-Index zum Einsatz, da er Gleichheits- und Bereichsvergleiche (=, <, >, BETWEEN) effizient unterstützt.
Funktionsweise eines B-Baums
Abschnitt betitelt „Funktionsweise eines B-Baums“Zum besseren Verständnis schauen wir uns zuerst den binären Suchbaum an. Daran ist gut erkennbar, dass die Suche viel schneller vonstatten geht, als von vorne bis hinten eine ganze Datenbank-Tabelle zu durchsuchen.
Ein Binärbaum ist ein sortierter Suchbaum, der so aufgebaut ist, dass ein beliebiger Knoten im Baum maximal zwei Nachfolgeknoten (Child Nodes) haben kann. Dabei gilt immer, dass der linke Nachfolgeknoten einen kleineren Wert bzw. der rechte Nachfolgeknoten einen größeren Wert haben muss. Das bewirkt, dass bei der Suche in jedem Schritt die Hälfte der Knoten, die noch zu durchsuchen wäre, nicht mehr betrachtet werden muss (vgl. binäre Suche in einer Liste). Dadurch reduziert sich die Anzahl der Knoten, die bei der Suche angeschaut werden müssen, enorm:
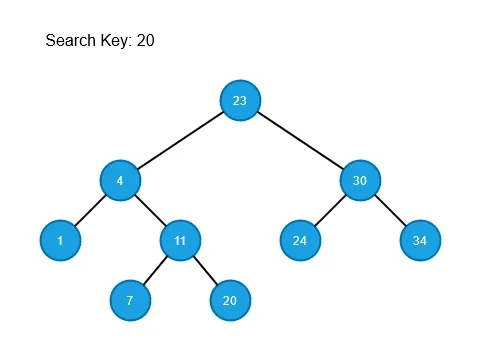
Die Anzahl der max. notwendigen Vergleiche (=Höhe eines Binärbaums) reduziert sich im Idealfall von n auf log₂(n), was ein enormer Unterschied ist! Wenn beispielsweise eine Tabelle n = 1 000 000 Einträge hat, dann wäre log₂(n) ≈ 20. Ein Binärbaum mit n = 1 000 000 Knoten hätte also im Idealfall nur eine Höhe von 20. So einen idealen Binärbaum nennt man ausbalanciert.
Ein Binärbaum muss aber nicht zwingend ausbalanciert sein. Ein nicht balancierter Baum kann im schlimmsten Fall sogar zu einer Liste degenerieren. Das passiert z.B., wenn neue Knoten in sortierter Reihenfolge in den Baum eingefügt werden. Dann ist der Baum einseitig “ausgeleiert” (= unausgeglichen) und der Vorteil eines Baums ist dahin, denn die Höhe ist wieder der einer linearen Liste - nämlich n (= wieder full table scan notwendig).

Ein B-Baum ist ähnlich wie ein binärer Suchbaum und zusätzlich mit den Eigenschaften, dass er
- immer ausbalanciert ist
- mehrere Werte pro Knoten speichern kann (sortiert)
- und mehr als nur zwei Nachfolgeknoten erlaubt (4, 8, 256, …).
Ein B-Baum z.B. der Ordnung 3 hat drei Nachfolgeknoten und 3 - 1 = zwei Werte pro Knoten:
[ 30 | 60 ] / | \[ 10 | 20 ] [ 40 | 50 ] [ 70 | 80 ]B-Bäume sind für Datenbanken optimiert. Ein Knoten entspricht in der Regel einer Datenseite (Page; PostgreSQL 8 KB, InnoDB 16 KB). Dadurch kann der Server mit einem Page-Read viele Schlüssel auf einmal laden, was die I/O-Kosten drastisch reduziert.
So kann ein B-Baum der Ordnung 100 mit nur drei Zugriffsebenen bereits über 1 Million Datensätze adressieren.
1. Ebene: Wurzel: 1 Page↓2. Ebene: 100 Pages (= 100 Nachfolgeknoten)↓3. Ebene: 100 × 100 Pages = 10 000 Pages → 1 000 000 DatensätzeWeiters gibt es noch B+-Bäume, die im Gegensatz zu B-Bäumen die Daten nur in den Blattknoten speichern (=Pages). Die inneren Knoten dienen nur der Navigation zu den Pages.
Für weitere Informationen siehe [2].
Invertierter Index
Abschnitt betitelt „Invertierter Index“Für die Volltextsuche ist ein B-Tree-Index meist ungeeignet (funktioniert dann nur für Präfix-Suche). Stattdessen gibt es den sog. invertierten Index. Dieser Index speichert, in welchem Datensatz welches Wort vorkommt:
Wort Datensatz-------------------------Bier [1, 4, 7, 12]Glas [4, 5, 7]Alkohol [2, 3]So kann die Suche direkt auf Wortlisten zugreifen → extrem schnell
In PostgreSQL gibt es eine leistungsfähige Volltextsuche integriert. Mehr dazu findest du unter [3] und [4].
Erstellung von Indizes
Abschnitt betitelt „Erstellung von Indizes“Indizes können nachträglich oder direkt bei der Tabellenerstellung definiert werden:
CREATE INDEX idx_last_name ON users (last_name);oder:
CREATE TABLE users ( id SERIAL PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), INDEX idx_last_name (last_name));Wichtige Indexarten
Abschnitt betitelt „Wichtige Indexarten“| Indexart | Beschreibung | Beispiel | Hinweise |
|---|---|---|---|
| Einfacher Index | Beschleunigt Abfragen auf einer Spalte | CREATE INDEX idx_name ON users(name); | Standard-Indextyp (B-Tree) |
| Mehrspaltiger Index | Kombination mehrerer Spalten | CREATE INDEX idx_name_full ON orders(customer_id, date); | Reihenfolge der Spalten ist entscheidend |
| Unique Index | Erzwingt eindeutige Werte | CREATE UNIQUE INDEX idx_mail ON users(email); | Wird oft automatisch bei PRIMARY KEY gesetzt |
| Volltextindex | Ermöglicht Textsuche (LIKE, MATCH) | MySQL/MariaDB: FULLTEXT; PostgreSQL: GIN + to_tsvector() | PostgreSQL bietet feinere Kontrolle über Sprachlexika |
| Räumlicher Index | Für geografische Daten | CREATE INDEX idx_loc ON points USING GIST (geom); | PostgreSQL nutzt GiST/SP-GiST; MySQL/MariaDB SPATIAL |
| Clustered Index | Physische Sortierung der Tabelle | InnoDB: PRIMARY KEY ist automatisch clustered | PostgreSQL hat Heap Tables, kann aber per CLUSTER manuell angeordnet werden |
Best Practice:
Abschnitt betitelt „Best Practice:“Indexe auf häufig genutzte Spalten anlegen:
- in
WHERE-Klauseln - in
JOIN-Bedingungen - in
ORDER BY-Klauseln (falls oft sortiert wird)
Aber: Nicht zu viele Indizes – jeder Index verlangsamt INSERT/UPDATE/DELETE, weil er mitgepflegt werden muss!
Vorteile von Indizes
Abschnitt betitelt „Vorteile von Indizes“-
Schnellere Suchabfragen Reduziert die Anzahl der gelesenen Datenseiten drastisch.
-
Optimierte Sortierungen und JOINs
ORDER BYundJOIN-Operationen profitieren von bestehenden Indizes. -
Schnelle Prüfung eindeutiger Werte Bei Unique- oder Primary-Key-Indizes wird sofort erkannt, ob ein Wert bereits existiert.
-
Selektiver Zugriff PostgreSQLs Planner nutzt Statistiken, um automatisch zu entscheiden, wann ein Index verwendet wird (Cost-based Optimization).
Nachteile
Abschnitt betitelt „Nachteile“-
Höherer Speicherverbrauch Jeder Index wird als separate Struktur abgelegt. Bei großen Tabellen kann das mehrere GB ausmachen.
-
Langsamere Schreibvorgänge INSERT, UPDATE und DELETE müssen Indexstrukturen mitpflegen. Besonders bei vielen Indizes pro Tabelle steigt der Aufwand.
-
Wartung und Fragmentierung Indizes müssen bei großen Datenänderungen regelmäßig überprüft oder neu aufgebaut werden. PostgreSQL:
REINDEX/VACUUM; MySQL/MariaDB:OPTIMIZE TABLE.
Beispiele zur Index-Optimierung
Abschnitt betitelt „Beispiele zur Index-Optimierung“Beispiel 1: WHERE-Bedingung auf einer eindeutigen Spalte (UNIQUE Index)
Abschnitt betitelt „Beispiel 1: WHERE-Bedingung auf einer eindeutigen Spalte (UNIQUE Index)“- Ohne Index → Full Table Scan
- Mit UNIQUE-Index → punktgenauer Zugriff; es gibt höchstens eine passende Zeile.
-- Variante A (direkt als Index)CREATE UNIQUE INDEX ux_users_email ON users(email);
-- Variante B (als Constraint; erzeugt intern ebenfalls einen eindeutigen Index)ALTER TABLE users ADD CONSTRAINT users_email_key UNIQUE (email);- Die Datenbank findet die Zeile über den eindeutigen Schlüssel in
O(log n)(B-Baum). - Zusätzlich wird Datenkonsistenz erzwungen: keine doppelten E-Mails.
- Hohe Selektivität ist hier per Definition gegeben (Unique).
Beispiel 2: Kombinierte WHERE-Bedingungen (Mehrspaltiger Index)
Abschnitt betitelt „Beispiel 2: Kombinierte WHERE-Bedingungen (Mehrspaltiger Index)“SELECT * FROM ordersWHERE customer_id = 15 AND order_date >= '2024-01-01';CREATE INDEX idx_orders_customer_date ON orders(customer_id, order_date);- Der Index ist komposit (mehrspaltig).
- Wichtig ist die Reihenfolge:
customer_idsteht zuerst, weil sie meist stärker filtert. - Wird nur
order_dateohnecustomer_idabgefragt, kann der Index nicht optimal genutzt werden („leftmost prefix rule“).
Analysiere mit EXPLAIN bzw. EXPLAIN ANALYZE, ob der Index verwendet wird (dazu später mehr)
Beispiel 3: ORDER BY optimieren
Abschnitt betitelt „Beispiel 3: ORDER BY optimieren“SELECT * FROM users ORDER BY last_name ASC;Ohne Index → Daten müssen sortiert werden (teuer bei vielen Zeilen).
CREATE INDEX idx_users_lastname_asc ON users(last_name ASC);- Die Datenbank kann die Zeilen direkt in sortierter Reihenfolge aus dem Index lesen.
- Spart CPU-Zeit und Speicher (kein Sort-Puffer nötig).
Ein Index auf Spalten, die oft in ORDER BY vorkommen, bringt deutlichen Performance-Gewinn – besonders bei LIMIT.
Beispiel 4: LIKE-Abfragen
Abschnitt betitelt „Beispiel 4: LIKE-Abfragen“SELECT * FROM products WHERE name LIKE 'Bier%';Mit Präfixsuche (Bier%) kann der Index verwendet werden, da das Muster am Anfang steht.
Mit %Bier% jedoch nicht, da der Beginn unbekannt ist.
CREATE INDEX idx_products_name ON products(name);PostgreSQL:
Mit einem text_pattern_ops-Index lässt sich die Optimierung bei LIKE explizit aktivieren:
CREATE INDEX idx_products_name_pattern ON products(name text_pattern_ops);MariaDB/MySQL:
Benutzt denselben B-Baum-Index für LIKE 'prefix%', nicht aber für '%suffix'. Die alphabetische Sortierung des Index ist bei der suffix-Suche sinnlos!
Lösungsansatz mit Volltext-Index:
CREATE FULLTEXT INDEX idx_products_name ON products(name);SELECT * FROM products WHERE MATCH(name) AGAINST('Bier');→ Sucht Begriffe an beliebiger Position im Text (vgl. '%pattern%').
Beispiel 5: Volltextsuche
Abschnitt betitelt „Beispiel 5: Volltextsuche“SELECT * FROM articles WHERE MATCH(content) AGAINST('Energie' IN NATURAL LANGUAGE MODE);Index in MySQL:
CREATE FULLTEXT INDEX idx_articles_content ON articles(content);PostgreSQL-Alternative:
CREATE INDEX idx_articles_fts ON articles USING GIN(to_tsvector('german', content));SELECT * FROM articles WHERE to_tsvector('german', content) @@ to_tsquery('Energie');Dieser Index speichert Wörter (Tokens) statt ganzer Strings → Suche nach Begriffen extrem schnell.
Beispiel 6: JOINs optimieren
Abschnitt betitelt „Beispiel 6: JOINs optimieren“SELECT o.id, c.nameFROM orders oJOIN customers c ON o.customer_id = c.idWHERE c.country = 'AT';Index anlegen:
CREATE INDEX idx_orders_customerid ON orders(customer_id);CREATE INDEX idx_customers_country ON customers(country);- Der JOIN auf
customer_idnutzt den ersten Index, um Bestellungen gezielt zu finden. - Der zweite Index beschleunigt die Filterung der Kunden nach Land.
Ohne Index müssten beide Tabellen vollständig durchsucht werden.
Beispiel 7: DISTINCT oder GROUP BY beschleunigen
Abschnitt betitelt „Beispiel 7: DISTINCT oder GROUP BY beschleunigen“SELECT DISTINCT category FROM products;Index anlegen:
CREATE INDEX idx_products_category ON products(category);Da der Index die Werte bereits sortiert enthält, kann die Datenbank Duplikate effizient erkennen — häufig ohne zusätzliche Sortierung.
Ein gut gesetzter Index kann Abfragen um ein Vielfaches beschleunigen – zu viele oder schlecht gewählte Indizes hingegen können das Gegenteil bewirken.
Ausführungsplan
Abschnitt betitelt „Ausführungsplan“Ein Ausführungsplan (Execution Plan) zeigt, wie die Datenbank eine SQL-Abfrage intern ausführt. Er beschreibt, wie Tabellen durchsucht, Indizes verwendet, Joins ausgeführt und Ergebnisse kombiniert werden.
Die Analyse eines Ausführungsplans ist entscheidend, um Engpässe und Optimierungspotenziale zu erkennen.
Ausgangssituation
Abschnitt betitelt „Ausgangssituation“Wir erstellen in PostgreSQL eine Tabelle people und befüllen diese mit 100 000 Datensätzen. Von den eingefügten Personen soll es ca. 5 % geben, die den Nachnamen „Dooley“ haben. Damit legen wir eine sog. Selektivität von 5% fest.
CREATE TABLE people ( id integer GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, firstname TEXT, lastname TEXT);
INSERT INTO people (firstname, lastname)SELECT md5(random()::text), -- firstname is always random CASE -- lastname is seeded with 5% "Dooley" WHEN random() < 0.05 -- ≈ 5 % true THEN 'Dooley' -- use "Dooley" ELSE md5(random()::text) -- use random string from random number ENDFROM generate_series(1, 100000); -- generate virtual rows1. Abfrage ohne Index
Abschnitt betitelt „1. Abfrage ohne Index“Schauen wir uns nun an, wie PostgreSQL folgende Abfrage ausführen würde:
EXPLAIN SELECT * FROM people WHERE lastname = 'Dooley';Ohne Index könnte das Ergebnis so aussehen:
Seq Scan on people (cost=0.00..1827.00 rows=5000 width=80) Filter: (lastname = 'Dooley')Das bedeutet:
- Seq Scan → vollständiger Tabellenscan
- PostgreSQL liest alle 100 000 Zeilen und filtert danach.
- Geschätzte Kosten: von 0.00 bis 1827.00
- Geschätzte Treffer: ca. 5000 Zeilen
Diese geschätzten Kosten bedeuten nicht Zeit in Sekunden oder Millisekunden, sondern sind relative Einheiten, die PostgreSQL intern verwendet, um verschiedene Ausführungsstrategien zu vergleichen. Kostenwerte können nicht direkt mit realer Zeit gleichgesetzt werden, korrelieren aber grob mit der Ausführungsdauer.
Du kannst also selbst einfach zwei verschiedene Kostenwerte so interpretieren, dass die niedrigeren Kosten die besseren sind.
2. Index erstellen
Abschnitt betitelt „2. Index erstellen“Nun erstellen wir einen Index auf den Nachnamen und schauen, was sich ändert:
CREATE INDEX idx_people_lastname ON people (lastname);Danach dieselbe Abfrage:
EXPLAIN SELECT * FROM people WHERE lastname = 'Dooley';Ein mögliches Ergebnis könnte sein:
Index Scan using idx_people_lastname on people (cost=0.15..213.17 rows=5000 width=80) Index Cond: (lastname = 'Dooley')Wir sehen nun:
- Index Scan using idx_people_lastname → Index wird aktiv verwendet
- PostgreSQL sucht gezielt über den Index nach passenden Zeilen
- Kosten sinken deutlich (von 1827 auf 213)
Statt eines Index Scan könnte sich der Planer von PostgreSQL auch für einen anderen Variante entscheiden:
- Seq Scan (alles lesen), wenn der Filter wenig selektiv ist oder die Tabelle klein/cached ist.
- Bitmap Index Scan + Heap Scan bei mittlerer Selektivität (typisch für ~1–10 % Treffer).
- Index Scan bei sehr hoher Selektivität (wenige Treffer).
- Kombination mehrerer Indizes per
BitmapAnd/BitmapOr, wenn mehrere Bedingungen passen.
3. Laufzeitmessung
Abschnitt betitelt „3. Laufzeitmessung“Neben den geschätzten Kosten kann auch die tatsächliche Laufzeit gemessen werden:
- EXPLAIN zeigt nur Schätzwerte (Plankosten).
- EXPLAIN ANALYZE führt die Abfrage tatsächlich aus und ergänzt reale Zeiten:
EXPLAIN ANALYZE SELECT * FROM people WHERE lastname = 'Dooley';Beispielausgabe:
Index Scan using idx_people_lastname on people (cost=0.15..213.17 rows=5000 width=80) (actual time=0.02..4.23 rows=4800 loops=1)| Feld | Bedeutung |
|---|---|
actual time | Reale Ausführungszeit in Millisekunden (min .. max Wert) |
rows | Tatsächlich zurückgegebene Zeilen |
loops | Wie oft der Schritt ausgeführt wurde (z. B. bei Joins) |
→ So lässt sich prüfen, ob die Kostenabschätzung des Optimizers korrekt war.
Zusammenfassend kann festgehalten werden:
-
Vollständiger Tabellenscan (Seq Scan / ALL) ist ineffizient, wenn ein passender Index existiert. ⇒ Unbedingt Index auf die Filterspalte anlegen.
-
Index Scan / ref / range ist effizient, wenn Suchbedingungen den Index nutzen. ⇒ Spalten mit
WHERE,JOIN,ORDER BYhäufig indexieren. -
Join-Strategie prüfen
-
Wenn mehrere Tabellen verbunden werden (
JOIN), wählt die Datenbank automatisch die effizienteste Methode. Der Optimizer übernimmt diese Auswahl automatisch. -
Bevorzugt
Nested Loop,Hash Join,Merge Joinje nach Datengröße.
-
-
Subqueries
- In PostgreSQL werden solche Konstrukte automatisch vom Optimizer in semantisch gleichwertige Joins (z.B. Hash Joins) umgewandelt.
Abfrageoptimierung
Abschnitt betitelt „Abfrageoptimierung“Oft werden SQL-Abfragen ungeschickt formuliert, sodass z. B. Indizes nicht oder nicht optimal genutzt werden können und damit die Ausführungszeiten unnötig hoch sind.
Es gibt einige zentrale Prinzipien, die beim Erstellen von Queries beachtet werden sollten:
- Sargability sicherstellen
Keine Funktionen oder Operationen auf Spalten im
WHERE/JOIN. → lieber Ausdrucksindex oder Vergleichslogik anpassen. - Datentypen konsistent halten Implizite Casts vermeiden, sonst werden Indizes nicht genutzt.
- Indizes gezielt nutzen
- Filter-, Join- und Sortierspalten indexieren.
- Für Textsuche geeigneten Index wählen:
- Prefix: B-Tree (+
text_pattern_ops) - Substring/Fuzzy:
pg_trgm+ GIN - Case-insensitive:
citextoderlower(...)-Index.
- Prefix: B-Tree (+
- Effiziente Filter- und Joinlogik
NOT EXISTSstattNOT IN(NULL-sicher).- Vor dem Aggregieren filtern (
WHEREstattHAVING, wo möglich).
- Sortierungen und Pagination optimieren
- Passende Mehrspaltenindizes für
ORDER BY+LIMIT. - Seek-Pagination statt
OFFSETfür große Resultsets.
- Passende Mehrspaltenindizes für
- I/O reduzieren
- Nur benötigte Spalten selektieren (kein
SELECT *). - Falls möglich: Index-Only Scans mit
INCLUDE-Spalten.
- Nur benötigte Spalten selektieren (kein
- Ausführungsplan analysieren
Mit
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)die tatsächliche Ausführung und I/O prüfen. Ohne Messung ist Optimierung reine Vermutung. Wenn der Plan einen Full Table Scan (Seq Scan / ALL) zeigt, ist eine alternative Query und/oder ein Index zu überlegen, um den Scan zu vermeiden.
Zu diesen Prinzipien schauen wir uns konkrete Beispiele (Antipatterns) an.
Häufige Antipatterns und bessere Alternativen
Abschnitt betitelt „Häufige Antipatterns und bessere Alternativen“1. Keine Funktionen auf Filterspalten (Sargability)
Abschnitt betitelt „1. Keine Funktionen auf Filterspalten (Sargability)“Schlecht
WHERE date(created_at) = CURRENT_DATEDie Funktion date(created_at) macht den Index auf created_at unbrauchbar.
Plan:
Seq Scan on orders Filter: (date(created_at) = CURRENT_DATE)Besser
WHERE created_at >= CURRENT_DATE AND created_at < CURRENT_DATE + INTERVAL '1 day'Plan:
Index Scan using idx_created_at on orders Index Cond: (created_at >= '2025-10-14 00:00:00' AND created_at < '2025-10-15 00:00:00')Tipp: Für häufige Sortierungen nach Zeit zusätzlich einen Index auf (created_at DESC) anlegen.
Man kann auch die Funktion auf der Filter-Spalte in den Index verlegen:
2. Ausdrucksindex statt Funktion im WHERE
Abschnitt betitelt „2. Ausdrucksindex statt Funktion im WHERE“Schlecht
Auch hier wird der Index nicht verwendet, weil lower(email) im Filter steht.
Plan:
Seq Scan on usersBesser
CREATE INDEX idx_users_lower_email ON users ((lower(email)));
Dadurch liegt schon der passende, spezielle Ausdfrucksindex vor.
Plan:
Index Scan using idx_users_lower_email on users3. Passende Datentypen wählen, implizite Casts vermeiden
Abschnitt betitelt „3. Passende Datentypen wählen, implizite Casts vermeiden“Schlecht
WHERE id = '42' -- id ist integerDer Index auf id wird nicht verwendet, weil ein impliziter Cast nötig ist.
Plan:
Seq Scan on t Filter: (id = '42'::text)Besser
WHERE id = 42Plan:
Index Scan using t_pkey on t Index Cond: (id = 42)4. LIKE/ILIKE richtig verwenden (Prefix vs. Substring)
Abschnitt betitelt „4. LIKE/ILIKE richtig verwenden (Prefix vs. Substring)“Schlecht
WHERE name LIKE '%miller%'Ein normaler B-Tree-Index hilft hier nicht, weil %miller% überall im Text matchen kann.
Plan:
Seq Scan on people Filter: (name LIKE '%miller%')Besser (Prefix mit B-Tree)
CREATE INDEX idx_people_name_pattern ON people (name text_pattern_ops);
SELECT * FROM people WHERE name LIKE 'Miller%';Achtung: LIKE 'Miller%' ist natürlich nicht semantisch gleich zu %Miller%.
Plan:
Index Scan using idx_people_name_pattern on people Index Cond: (name >= 'Miller' AND name < 'Milles')Speziell in PostgreSQL gibt es auch eigene Erweiterungen für Textsuche:
Substring- oder Fuzzy-Suche mit Trigrammen
CREATE EXTENSION IF NOT EXISTS pg_trgm; -- load PostgreSQL-Extension for fast substring/fuzzy text searchCREATE INDEX idx_people_name_trgm ON people USING GIN (name gin_trgm_ops);
SELECT * FROM people WHERE name LIKE '%miller%';Plan:
Bitmap Heap Scan on people Recheck Cond: (name LIKE '%miller%') -> Bitmap Index Scan on idx_people_name_trgm Index Cond: (name LIKE '%miller%')5. EXISTS/NOT EXISTS statt (NOT) IN mit Subquery
Abschnitt betitelt „5. EXISTS/NOT EXISTS statt (NOT) IN mit Subquery“Schlecht
WHERE id NOT IN (SELECT id FROM b) -- NULL-Fallen, oft teuerWenn b.id NULL enthält, liefert die Bedingung gar keine Zeilen zurück.
Außerdem muss PostgreSQL alle Werte aus b materialisieren.
Plan:
Seq Scan on a Filter: (NOT (a.id = ANY (SubPlan))) SubPlan 1 -> HashAggregate on b (id) -- Materialisierung aller b.id -> Seq Scan on bBesser: Anti-Join (NULL-sicher und performanter)
WHERE NOT EXISTS (SELECT 1 FROM b WHERE b.id = a.id)
-- oder gleichwertiger JOINSELECT a.*FROM aLEFT JOIN b ON b.id = a.idWHERE b.id IS NULL;Hier muss nur überprüft werden, ob eine bestimmte id in b vorhanden ist, was sehr schnell geht.
Plan:
Hash Anti Join Hash Cond: (a.id = b.id) -> Seq Scan/Index Scan on a -- mit sonstigen Filtern -> Hash -> Index/Seq Scan on b using b_id_idx6. LIMIT + ORDER BY: Sort vermeiden
Abschnitt betitelt „6. LIMIT + ORDER BY: Sort vermeiden“Schlecht
SELECT * FROM logsWHERE service = 'api'ORDER BY created_at DESCLIMIT 50; -- ohne passenden IndexOhne passenden Index muss PostgreSQL erst alle Treffer sammeln und danach sortieren.
PostgreSQL liest zunächst alle Zeilen mit service = 'api' (oft über Seq Scan oder Bitmap-Index-Plan).
Danach muss es diese Treffer sortieren (Sort-Node) nach created_at DESC.
Erst dann kann es die obersten 50 zurückgeben.
Plan:
Seq Scan on logs Filter: (service = 'api') -> Sort -> LimitBesser
CREATE INDEX logs_service_created_at_idxON logs (service, created_at DESC)INCLUDE (id, message); -- optional, für Index-Only Scans
SELECT id, created_at, messageFROM logsWHERE service = 'api'ORDER BY created_at DESCLIMIT 50;Der Mehrspaltenindex ist nach service gruppiert und innerhalb jeder service-Gruppe bereits nach created_at DESC sortiert.
Der Planner kann die Zeilen direkt in der gewünschten Reihenfolge lesen (Index Scan in Index-Reihenfolge).
Dank LIMIT 50 kann er nach 50 passenden Zeilen stoppen – es ist kein Sort nötig.
Plan:
Index Scan using logs_service_created_at_idx on logs Index Cond: (service = 'api') -> Limit (Stop after 50)7. Aggregation: erst filtern, dann gruppieren
Abschnitt betitelt „7. Aggregation: erst filtern, dann gruppieren“Schlecht
SELECT product_id, sum(qty)FROM order_itemsGROUP BY product_idHAVING max(created_at) >= now() - interval '30 days';Plan:
GroupAggregate Filter: (max(created_at) >= (now() - '30 days'::interval)) -> Seq Scan on order_itemsBesser
SELECT product_id, sum(qty)FROM order_itemsWHERE created_at >= now() - interval '30 days'GROUP BY product_id;WHERE reduziert die Eingabemenge vor der Aggregation → weniger Speicher, weniger I/O.
Plan:
HashAggregate (group by product_id) -> Bitmap Heap Scan on order_items Recheck Cond: (created_at >= now() - '30 days'::interval) -> Bitmap Index Scan on idx_orderitems_created_at8. SELECT *
Abschnitt betitelt „8. SELECT *“Schlecht
SELECT * FROM orders WHERE id = 123Plan:
Index Scan using orders_pkey on orders Index Cond: (id = 123) -- Heap fetch für alle restlichen Spalten wegen SELECT *Besser
SELECT id, status, total FROM orders WHERE id = 123Plan:
Index Scan using orders_pkey on orders Index Cond: (id = 123) -- Heap fetch (nur noch für id,status,total)Noch besser (Index-Only Scan):
CREATE INDEX orders_id_status_total_idx ON orders (id) INCLUDE (status, total);Plan:
Index Only Scan using orders_id_status_total_idx on orders Index Cond: (id = 123)Index-Only Scans vermeiden den Zugriff auf den Heap vollständig, wenn die Daten im Visibility Map als sichtbar markiert sind.
Quellen:
- [1] Build the Forest in Python Series: Binary Search Tree, https://www.codeproject.com/articles/Build-the-Forest-in-Python-Series-Binary-Search-Tr
- [2] Online-Buch zu indexbasiertem SQL Tuning, https://use-the-index-luke.com/de/
- [3] Volltextsuche mit PostgreSQL, https://www.credativ.de/blog/credativ-inside/volltextsuche-mit-postgresql
- [4] PostgreSQL 18.0 Documentation - Chapter 12. Full Text Search, https://www.postgresql.org/docs/current/textsearch.html
- [5] PostgreSQL Documentation: The EXPLAIN Command, https://www.postgresql.org/docs/current/using-explain.html
- [6] MySQL 8.0 Reference Manual: EXPLAIN Output Format, https://dev.mysql.com/doc/refman/8.0/en/explain-output.html