3. Datenmodellierung
Datenmodellierung
Abschnitt betitelt „Datenmodellierung“Datenmodellierung beschreibt, wie Informationen eines realen Bereichs so strukturiert werden, dass sie in einer Datenbank zuverlässig gespeichert und ausgewertet werden können. Das Ziel ist dabei eine klare, konsistente Struktur, die korrekte Auswertungen ermöglicht und langfristig wartbar bleibt.
Schritte der Datenmodellierung
Abschnitt betitelt „Schritte der Datenmodellierung“Die einzelnen Schritte der Datenmodellierung sind:
-
Problem verstehen: Ziele, Fragen und benötigte Informationen sammeln (z. B. für eine Schulbibliothek: Bücher, Ausleihen, Personen). Dazu gibt es eine Disziplin namens Requirements Engineering (Anforderungsanalyse). Das Ergebnis ist ein Lasten- oder Pflichtenheft.
-
Entitäten bestimmen: Dinge/Objekte mit Bedeutung (Buch, Schüler, Lehrer). Achten Sie dabei auf Homonyme (z. B. “Klasse” als Schulklasse, Programmierklasse oder Klassenraum).
-
Attribute festlegen: Eigenschaften der Entitäten (Titel, ISBN, Name, Klasse).
-
Beziehungen und Kardinalitäten definieren: Wie Entitäten zusammenhängen (ein Buch - viele Ausleihen; eine Ausleihe - genau ein Buch, genau eine Person).
-
Schlüssel wählen: Primärschlüssel eindeutig, Fremdschlüssel verknüpfen Tabellen. Was macht die einzelnen Entitäten eindeutig identifizierbar?
-
ER-Modell zeichnen: Entitäten, Attribute, Beziehungen visualisieren.
-
Normalisieren: Redundanz und Anomalien vermeiden (1NF: atomare Werte; 2NF/3NF: Abhängigkeiten trennen).
-
Datentypen und Constraints festlegen: z. B. NOT NULL, UNIQUE, CHECK.
-
Relationales Schema ableiten: Tabellenstruktur aus dem ER-Modell erstellen.
-
Implementieren und testen: SQL-DDL ausführen, Beispieldaten einfügen, typische Abfragen prüfen.
-
Iterativ verbessern: Feedback nutzen, Modell bei neuen Anforderungen anpassen - und das von vorne.
Abstraktionen
Abschnitt betitelt „Abstraktionen“Beim Erstellen eines Datenmodells wird nicht jedes einzelne Detail der Realität 1:1 übernommen. Stattdessen werden Informationen so geordnet, dass sie für ein System sinnvoll und beherrschbar sind. Dazu werden Objekte der realen Welt betrachtet, ihre Eigenschaften gesammelt und danach strukturiert. Dieser Schritt heißt Abstraktion.
Grundbegriffe: Objekt und Klasse
Abschnitt betitelt „Grundbegriffe: Objekt und Klasse“-
Objekt: ein konkretes, einzelnes Ding aus der realen Welt. Beispiel: Ein bestimmtes Auto mit dem Kennzeichen XYZ-123, ein konkreter Schüler oder Schülerin, etc.
-
Klasse: eine Menge gleichartiger Objekte mit gemeinsamen Merkmalen.
Beispiel: Die Klasse “Auto” umfasst alle zugelassenen Autos, die Klasse “Schüler” umfasst alle einzelnen Schüler und Schülerinnen.
Eine Klasse beschreibt also, welche Eigenschaften ihre Objekte haben (z. B. Hersteller, Modell, Baujahr oder Vorname, Nachname, Geburtsdatum), während ein Objekt konkrete Werte für diese Eigenschaften besitzt (z. B. “VW”, “Golf”, “2019” oder “Kevin”, “Maier”, “2005-05-15”).
Zentrale Abstraktionskonzepte
Abschnitt betitelt „Zentrale Abstraktionskonzepte“1) Klassifikation
Abschnitt betitelt „1) Klassifikation“Gleichartige Objekte mit gemeinsamen Eigenschaften werden zu Klassen zusammengefasst. Welche Dinge Ihrer Analyse sind gleich oder sehr, sehr ähnlich?

Beispiel: Aus einzelnen Tieren wird die Klasse “Säugetier”. Aus einzelnen Büchern entsteht die Klasse “Buch”.
2) Aggregation (Ganzes-Teil-Beziehung)
Abschnitt betitelt „2) Aggregation (Ganzes-Teil-Beziehung)“Eine neue Klasse wird aus anderen Klassen zusammengesetzt. Ein Objekt kann also Teile besitzen, die selbst wieder Objekte anderer Klassen sind. Können Sie “X besteht aus …” definieren?

Beispiel: Die Klasse “Auto” besteht u. a. aus Motor, Karosserie und Rädern. Ein “Computer” aggregiert CPU, Arbeitsspeicher und Festplatte.
3) Generalisierung (Verallgemeinerung) / Spezialisierung
Abschnitt betitelt „3) Generalisierung (Verallgemeinerung) / Spezialisierung“Zwischen Klassen wird eine Ist-ein-Beziehung hergestellt. Eine allgemeinere Klasse fasst Eigenschaften zusammen, die allen zugehörigen spezielleren Klassen gemeinsam sind. Beispiel: “Tier” verallgemeinert “Vogel”, “Reptil” und “Säugetier”. Die gemeinsamen Eigenschaften (z. B. “Lebewesen”, “Atmung”) liegen in “Tier”. “Vogel” ergänzt spezielle Merkmale (z. B. “Flügel”).
Vererbung: Eigenschaften der allgemeinen Klasse werden von den spezialisierten Klassen geerbt, z.B. alles was ein “Säugetier” kann, kann auch ein “Hund” oder “Katze”.

Generalisierung kann auch über viele Stufen gehen: “Tier” zu “Säugetier” zu “Hund” zu “Schäferhund”. Dabei werden die Objekte in den einzelnen Stufen immer “genauer” (spezialisierter). Während “Tier” noch recht allgemein ist und “Säugetier” bereits spezifischer, wird “Hund” noch genauer und “Schäferhund” schließlich sehr spezifisch.
Generalisierung: von einzelnen Klassen auf ein allgemeine übergeordnete Klasse schließen, z.B von “Hund” und “Katze” auf “Säugetier”. Spezialisierung: von einer allgemeinen Klasse auf detailliertere Sub-Klassen schließen, z.B. von “Säugetier” zu “Hund” und “Katze”.
4) Assoziation (Beziehung)
Abschnitt betitelt „4) Assoziation (Beziehung)“Objekte oder Klassen können in Beziehung zueinander stehen. Diese Beziehungen können zwischen zwei oder mehreren Klassen auftreten und zusätzlich Rollen, Richtung und Kardinalitäten besitzen.
Beispiel: “Schüler” —“besucht” — “Schule” (viele Schüler besuchen eine Schule; eine Schule hat viele Schüler). Beispiel: “Kunde bestellt Bestellung”, “Lehrer hält Kurs”.
Assoziation sind meistens Verben: “besucht”, “bestellt”, “spielt”, “kauft”, “bekommt”, “benennt”, “fliegt”, …

Tatsächlich ist die Generalisierung auch eine spezielle Art einer Assoziation: “ist” und die Aggregation ebenfalls: “hat”.
5) Identifikation (Schlüssel)
Abschnitt betitelt „5) Identifikation (Schlüssel)“Damit ein Objekt eindeutig erkannt werden kann, werden bestimmte Eigenschaftswerte als Schlüssel definiert.

Beispiel: ISBN identifiziert ein Buch eindeutig; das Kürzel identifiziert eine Person innerhalb einer Schule; bei Autos kann die Fahrzeug-Identifikationsnummer (FIN) oder auch das Kennzeichen dienen.
Zusammengefasst
Abschnitt betitelt „Zusammengefasst“- Klassifikation ordnet ähnliche Dinge zu Klassen.
- Aggregation beschreibt “besteht aus”-Strukturen.
- Generalisierung/Spezialisierung organisiert Gemeinsamkeiten und Unterschiede über Vererbung.
- Assoziation verbindet Klassen durch Beziehungen.
- Identifikation stellt Eindeutigkeit durch Schlüssel sicher.
Diese Konzepte helfen, komplexe Realitäten klar, wiederverwendbar und fehlerarm in Datenmodellen abzubilden.
Das Entity-Relationship-Modell (ER-Modell)
Abschnitt betitelt „Das Entity-Relationship-Modell (ER-Modell)“Das Entity-Relationship-Modell (ER-Modell, ERM) ist ein weit verbreitetes grafisches Hilfsmittel für den Entwurf von Datenbanken. Es wird auch in anderen Bereichen der Informatik genutzt, um Teile der realen Welt abzubilden. Das ERM ist unabhängig von einem konkreten Datenmodell und nicht an technische Einschränkungen einer bestimmten Implementierung gebunden. Entwickelt wurde es 1976 von Peter Chen. Mit dem ER-Modell lassen sich die konzeptionellen Entwürfe einer Datenbank übersichtlich darstellen; eine häufig verwendete Darstellungsform heißt nach ihrem Urheber “Chen-Notation”. Es gibt aber auch andere Notationen, z.B. die “Krähenfuss-Notation”.
Die Grundbausteine des ER-Modells sind:
- Entities (Entitäten) - die Dinge oder Objekte, über die Informationen gespeichert werden.
- Relationships (Beziehungen) - die Verknüpfungen zwischen diesen Entitäten.
- Attribute - Merkmale, die sowohl Entitäten als auch Beziehungen genauer beschreiben.
Von einer Entitätsmenge oder einer Beziehungsmenge können beliebig viele einzelne Objekte vorkommen.
Für erweiterte Beziehungsarten gibt es das EERM (Extended/Erweitertes ER-Modell). Es ergänzt das klassische ERM unter anderem um:
- Aggregation (Teil-von / Part-of) - bildet zusammengehörige Objekte als Ganzes ab.
- Generalisierung/Spezialisierung (Ist-ein / Is-a) - ordnet gemeinsame Eigenschaften einer Oberklasse zu und führt Unterklassen für Besonderheiten ein.
- Weitere Beziehungsformen, die eine detailliertere, semantisch reichere Modellierung ermöglichen.
So unterstützt das (E)ER-Modell eine klare, verständliche und systematische Planung von Datenstrukturen.
Das ER-Modell nach Peter Chen - die Chen Notation
Abschnitt betitelt „Das ER-Modell nach Peter Chen - die Chen Notation“Die Chen Notation ist die erste grafische Darstellung des ER-Modells, die Entitäten, Beziehungen und Attribute übersichtlich visualisiert. Sie verwendet Rechtecke für Entitäten, Rauten für Beziehungen und Ovale für Attribute. Die Kardinalitäten werden durch Linien und Beschriftungen dargestellt.

Peter Chen stellte 1976 in seinem Artikel “The Entity-Relationship Model - Toward a Unified View of Data” das ER-Modell vor. Er beschreibt darin, wie man die realen Welt durch Entitäten und deren Beziehungen zueinander abbilden kann. Dieses Modell bildet die Grundlage für viele moderne Datenbankdesigns und -implementierungen.
Entität, Entity-Typ und Entitätsmenge
Abschnitt betitelt „Entität, Entity-Typ und Entitätsmenge“Entität (Entity)
Eine Entität ist ein eindeutig unterscheidbares “Ding” aus der realen Welt. Das kann eine Person, ein Gegenstand, eine Firma, ein Hund, ein Raum oder ein Projekt sein. Entitäten unterscheiden sich durch ihre Eigenschaften (Attribute) und deren Werte.
Objekt und Instanz sind Synonyme für Entität. Eine Entität ist also ein konkretes Objekt mit individuellen Attributwerten.
Beispiel: “Mitarbeiter Schmidt”, “Projekt 1009”, “Abteilung Forschung”, “Mike der Hund”, “Ferdinand der Kater”.
Entity-Typ
Der Entity-Typ beschreibt eine Klasse gleichartiger Entitäten - also Dinge, die durch die gleichen Attribute beschrieben werden. Bei der Modellierung arbeitet man normalerweise mit den Entity-Typen, nicht mit einzelnen Entitäten.
Grafisch werden Entity-Typen oft als Rechtecke dargestellt.
Beispiele für Entity-Typen: Mitarbeiter, Abteilung, Projekt, Hund, Kater.
Entitätsmenge (Entity-Set)
Eine Entitätsmenge ist die Sammlung aller Entitäten eines Entity-Typs zu einem bestimmten Zeitpunkt. Alle Elemente darin haben die gleichen Attribute, aber unterschiedliche Attributwerte.
Entitätsmengen können sich über die Zeit ändern (neue Entitäten kommen hinzu, andere fallen weg).
Beispiele: Alle Mitarbeiter, Alle Abteilungen, Alle Projekte, Alle Hunde, Alle Kater.
Attribute
Abschnitt betitelt „Attribute“Attribute (Eigenschaften) beschreiben Merkmale von Entitäten, Entity-Typen, Beziehungen oder Beziehungstypen.
Jedes Attribut hat:
- einen Namen (z. B. Geburtsdatum, Preis, Bezeichnung) und
- einen Wert (z. B. 12.03.2008, 19,99, “Mathematik”, “Mike”).
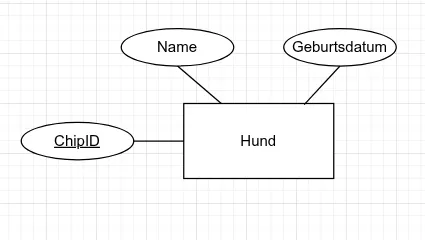
Attribute werden in der Chen-Notation als Ovale dargestellt und mit einer Linie mit dem Entity-Typ verbunden.

Die Domäne legt fest, welche Werte ein Attribut überhaupt annehmen darf, der Wertebereich. Das kann sein:
- eine feste Liste von erlaubten Werten (z. B. Januar, Februar, …),
- ein Bereich (z. B. Zahlen 0-999 oder Buchstaben A-G, 1.5-2.5),
- eine Mengen- bzw. Datentypangabe (z. B. natürliche Zahl, reelle Zahl, Datum, Boolean).
Damit wird klar, welche Art von Daten für ein Attribut zulässig ist und welche nicht - wichtig für korrekte und konsistente Daten in der Datenbank. Die Domäne beschreibt den Wertebereich eines Attributs.
Schlüsselattribute
Abschnitt betitelt „Schlüsselattribute“- Ein Schlüssel besteht aus einem oder mehreren Attributen.
- Er soll so kurz wie möglich, aber so lang wie nötig sein (Minimalitätsprinzip).
Künstlicher Schlüssel (Surrogate Key)
- Falls kein vorhandenes Attribut (oder keine Attributkombination) eindeutig identifiziert, wird ein künstliches Attribut ergänzt (z. B. eine laufende Nummer/ID).
- Dieses Attribut erhält für jede Entität einen einzigartigen Wert und dient als Schlüssel.
Primärschlüssel (Primary Key)
- Der Primärschlüssel identifiziert jede Entität eindeutig; sein Wert kommt in der Entitätsmenge nur einmal vor.
- Das Attribut, das eine Entität eindeutig macht, heißt identifizierendes Attribut.
- Reicht ein Attribut nicht aus, kann der Primärschlüssel zusammengesetzt sein (mehrere identifizierende Attribute).
- Ein Entity-Typ kann mehrere mögliche Schlüssel (Kandidaten-/Alternativschlüssel) haben, aber es wird genau einer als Primärschlüssel festgelegt.
- In ER-Diagrammen werden die Attribute des Primärschlüssels unterstrichen dargestellt.
Beispiele (zur Einordnung)
- Person: Matrikelnummer (eindeutig) → guter Primärschlüssel.
- Person: Vorname + Nachname (nicht eindeutig) → ungeeignet; ggf. Geburtsdatum hinzufügen, oder besser eine Personen-ID verwenden.
- Produkt: Artikelnummer statt Bezeichnung (weil Bezeichnungen sich ändern oder doppelt vorkommen können).
Mehrwertige Attribute
Abschnitt betitelt „Mehrwertige Attribute“Einige Attribute können mehrere Werte annehmen (z. B. Telefonnummern einer Person) oder sich aus mehreren Teilen zusammensetzen (z. B. Straße, Hausnummer, PLZ, Ort für eine Adresse). In der Chen Notation werden solche Attribute als doppelte Ovale dargestellt.

Beziehungen (Relationships)
Abschnitt betitelt „Beziehungen (Relationships)“- Beziehungen zeigen Wechselwirkungen oder Abhängigkeiten zwischen Entitäten.
- Auch Beziehungen können Attribute besitzen (z. B. Rolle im Projekt, Einstellungsdatum in einer “arbeitet-an”-Beziehung).
Beziehungsmenge (Association)
- Eine Beziehungsmenge ist eine Sammlung gleichartiger Beziehungen, die bestimmte Entitätsmengen miteinander verknüpft (z. B. alle “Mitarbeiter-arbeitet-an-Projekt”-Paare).
Beziehungstyp
- Der Beziehungstyp ist - wie der Entity-Typ - die Abstraktion: Er beschreibt welche Art von Verknüpfung zwischen welchen Entity-Typen besteht.
- In ER-Diagrammen wird ein Beziehungstyp als Raute dargestellt.
- Die Raute ist über Kanten mit den beteiligten Entity-Typen verbunden.
- Der Name des Beziehungstyps kann in der Raute stehen (z. B. “arbeitet_an”, “besitzt”, “gehört_zu”).

- Beziehungen können eigene Attribute haben, z. B. die Tätigkeit einer Person in einem Projekt oder der Einsatzanteil in %.
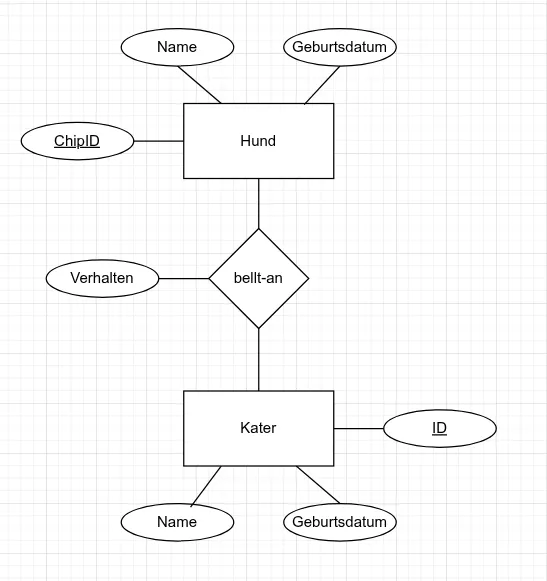
Auch die Anzahl der beteiligten Entity-Typen (Grad) kann variieren. Meistens hat man 2 Entitäten, es sind aber auch mehr möglich: 3 oder noch mehr.
- Ein Produkt setzt sich aus Bauteilen verschiedener Lieferanten zusammen (3 Entitäten: Produkt, Bauteil, Lieferant: eine ternäre Beziehung).
Generalisierung/Spezialisierung
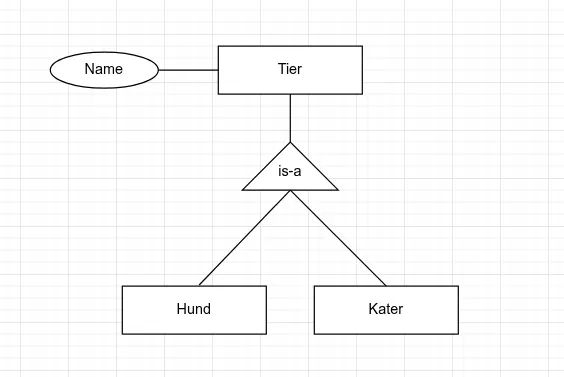
Abschnitt betitelt „Generalisierung/Spezialisierung“Generalisierung und Spezialisierung sind im Grunde spezielle Arten von Beziehungen zwischen Entity-Typen. Um diese Beziehungen in der Chen Notation darzustellen, wird eine Raute mit dem Namen “ist” verwendet. Die Raute wird mit Linien zu den beteiligten Entity-Typen verbunden.
Als Alternative dazu hat sich auch die Darstellung mit einem Dreieck durchgesetzt, das die Generalisierungs-/Spezialisierungsbeziehung symbolisiert. Das Dreieck wird mit Linien zu den beteiligten Entity-Typen verbunden, wobei die Spitze des Dreiecks auf den allgemeineren Entity-Typ zeigt.
Schwache Entitäten
Abschnitt betitelt „Schwache Entitäten“In vielen Fällen sind Entitäten selbstständig: Sie können innerhalb ihrer Entitätsmenge eindeutig identifiziert werden.
Es gibt jedoch auch Entitäten, die nur zusammen mit dem Schlüssel eines übergeordneten (dominanten) Entitätstyps eindeutig sind. Diese nennt man schwache oder abhängige Entitäten.
Beispiele:
- Bankverbindung eines Kunden mit Einzugsermächtigung: Wird der Kunde gelöscht, muss auch die Einzugsermächtigung gelöscht werden (Abhängigkeit).
- Klasse einer Schule: Eine Klasse existiert nur im Zusammenhang mit genau dieser Schule; Teile ihrer Beschreibung hängen von Attributen der Schule ab.
Darstellung in Diagrammen:
- Schwache Entitäten werden als doppelte Rechtecke gezeichnet.
In der Fachliteratur finden sich teilweise andere Kennzeichnungen (z. B. doppelter oder dicker Rahmen, doppelte Linien, Pfeile in andere Richtung).

Kardinalitäten
Abschnitt betitelt „Kardinalitäten“Die Kardinalität legt fest, wie viele Entitäten einer Entitätsmenge mit wie vielen Entitäten einer anderen Entitätsmenge verknüpft sein können (z. B. wie viele Mitarbeiter an einem Projekt mitarbeiten - und umgekehrt).
-
Genau eine Zuordnung (1)
Eine Entität ist mit genau einer Entität der anderen Seite verbunden.
Beispiel: Jede Rechnung gehört genau einem Kunden → (1:1), wenn das auch umgekehrt gilt.
-
Eine oder mehrere Zuordnungen (1..n bzw. n)
Eine Entität ist mit einer oder mehreren Entitäten der anderen Seite verbunden.
Beispiel: Ein Projekt hat eine oder mehrere Mitarbeiter → (1:n).
-
Viele-zu-viele (m:n)
Mehrere Entitäten auf der einen Seite können mit mehreren auf der anderen Seite verbunden sein.
Beispiel: Mitarbeiter arbeiten an mehreren Projekten, und Projekte haben mehrere Mitarbeiter → (m:n).
Optionalität (falls benötigt):
- 0..1: keine oder eine Zuordnung (optional, höchstens eine).
- 0..n: keine, eine oder viele Zuordnungen (optional, beliebig viele).
Beispiel
Abschnitt betitelt „Beispiel“-
Entitäten bestimmen: Markieren Sie sich mögliche Entitäten im Text. Kandidaten dafür sind meistens Substantive.
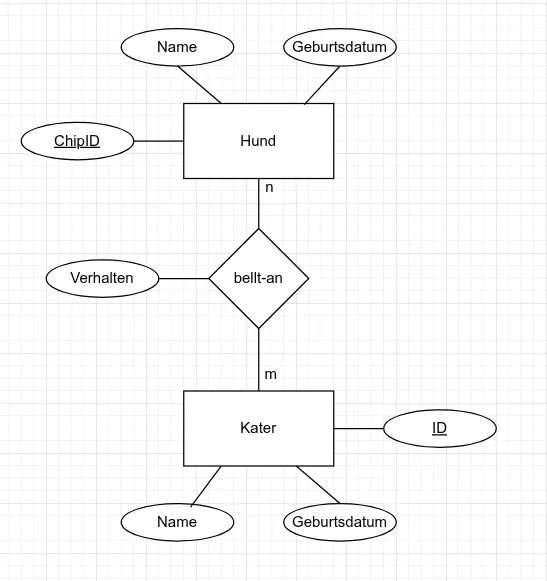
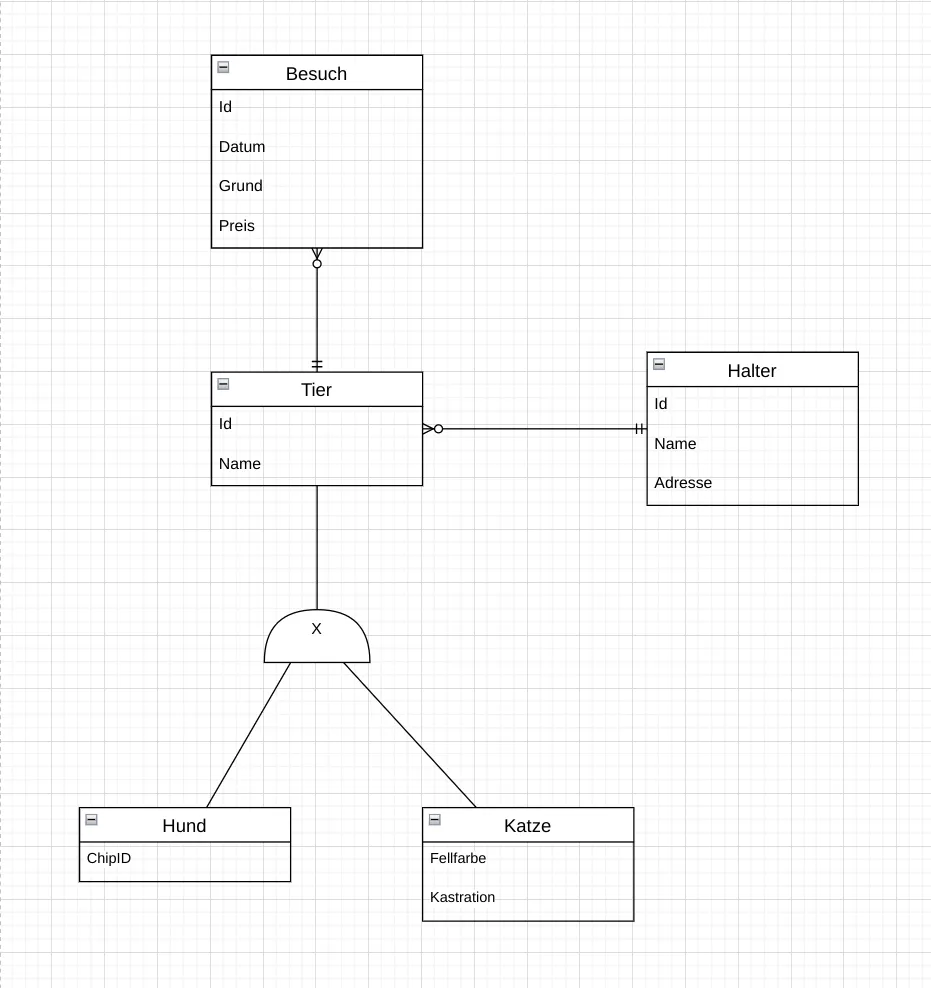
In einer Kleintierpraxis werden Haustiere ihrer Besitzer verwaltet. Jeder Halter kann mehrere Tiere besitzen, ein Tier gehört jedoch genau einem Halter. Jedes Tier ist entweder ein Hund oder ein Kater. Jeder Besuch hat ein Datum, einen Behandlungsgrund und eine Rechnungssumme. Für Hunde werden rassespezifische Angaben und eine optionale Chipnummer festgehalten; für Kater werden u. a. Fellfarbe und der Kastrationsstatus dokumentiert.
Wenn Sie unsicher sind, ob etwas eine Entität ist, fragen Sie sich: “Ist das ein Ding, über das ich Informationen speichern möchte?” Wenn ja, ist es wahrscheinlich eine Entität.
Im Text gibt es Pluralformen (z. B. “Tiere”, “Besitzer”). Diese deuten oft auf Entitätsmengen hin. Die Singularform (z. B. “Tier”, “Besitzer”) wird als Entity-Typ verwendet.
Es kann auch Homonyme und Synonyme geben, z.B. “Halter” und “Besitzer” - beides dasselbe. Wählen Sie einen Begriff und bleiben Sie dabei.
Achten Sie auch darauf, ob es einen Begriff gibt, welcher das Gesamtsystem beschreibt (z. B. “Kleintierpraxis”). Dies könnte ebenfalls eine Entität sein, meistens ist das aber der Kontext, der Titel des Modells oder der Datenbank insgesamt.
Zusammengefasst:
- Model: “Tierarztpraxis”
- Entity-Typen: “Halter”, “Tier”, “Hund”, “Kater”, “Besuch”
-
Attribute festlegen: Welche Eigenschaften (Attribute) haben die Entitäten? Welche Informationen wollen Sie über sie speichern?
Aus dem Text ergeben sich folgende Attribute:
- Halter: Name, Adresse - diese Attribute erscheinen nicht in der Faktenbasis, machen aber Sinn, um den Halter zu identifizieren und zu kontaktieren. Seien Sie grundsätzlich vorsichtig mit Attributen, die nicht explizit genannt werden! Für Sie mögen sie sinnvoll erscheinen, aber vielleicht sind sie es im gegebenen Kontext nicht oder bekommen aber auch eine andere Bedeutung.
- Tier: Name - auch dieses Attribut erscheint nicht in der Faktenbasis, macht aber Sinn, um das Tier zu benennen.
- Hund (spezialisiert von Tier): Rasse, Chipnummer
- Kater (spezialisiert von Tier): Fellfarbe, Kastrationsstatus
- Besuch: Datum, Grund, Preis
-
Beziehungen und Kardinalitäten definieren: Wie hängen die Entitäten zusammen? Welche Beziehungen gibt es zwischen ihnen?
Aus dem Text ergeben sich folgende Beziehungen:
- Halter besitzt Tier (1:n): Ein Halter kann mehrere Tiere besitzen, aber jedes Tier gehört genau einem Halter.
- Tier hat Besuch (1:n): Ein Tier kann mehrere Besuche haben, aber jeder Besuch gehört genau einem Tier.
- Tier ist entweder Hund oder Kater: Jedes Tier ist genau ein Hund oder ein Kater. Das ist eine Generalisierung/Spezialisierung.
-
Schlüssel wählen: Welche Attribute machen die Entitäten eindeutig identifizierbar?
Aus dem Text ergeben sich folgende Schlüsselattribute:
- Halter: Eine Id als laufende Nummer. Der Name allein reicht nicht aus, da mehrere Halter denselben Namen haben können.
- Tier: Ebenfalls eine Id als laufende Nummer. Der Name allein reicht nicht aus, da mehrere Tiere denselben Namen haben können.
- Hund: Chipnummer (optional, aber wenn vorhanden, eindeutig). Das ist zusätzlich zur Id des Tiers.
- Kater: Keine eindeutigen Attribute im Text genannt, also nur die Id des Tiers.
- Besuch: Auch hier eine Id als laufende Nummer. Das Datum allein reicht nicht aus, da ein Tier mehrere Besuche am selben Tag haben könnte.
-
ER-Modell zeichnen: Zeichnen Sie das ER-Diagramm in Chen Notation basierend auf den oben definierten Entitäten, Attributen, Beziehungen und Kardinalitäten.
 Abb. 6.16: ER-Diagramm einer Kleintierpraxis in Chen Notation.
Abb. 6.16: ER-Diagramm einer Kleintierpraxis in Chen Notation.
Information-Engineering-(IE)-Notation, Martin-Notation oder Krähenfuss-Notation
Abschnitt betitelt „Information-Engineering-(IE)-Notation, Martin-Notation oder Krähenfuss-Notation“Die Information-Engineering-(IE)-Notation, auch Martin-Notation oder Krähenfuss-Notation genannt, ist eine alternative grafische Darstellung des Entity-Relationship-Modells (ERM). Sie wurde von James Martin entwickelt und zeichnet sich durch ihre klare und prägnante Darstellung von Entitäten, Beziehungen und Kardinalitäten aus.
Die Chen-Notation war die erste grafische Darstellung des ER-Modells und war damit sehr einflussreich und erfolgreich. Allerdings wurde sie im Laufe der Zeit als etwas komplex und schwerfällig empfunden, insbesondere bei der Darstellung von Kardinalitäten und optionalen Beziehungen.
Die häufigen Nachteile der Chen-Notation:
- Zu viele Symbole: Entitäten, Beziehungen (Rauten) und Attribute (Ovale) machen große Modelle schnell unübersichtlich. Es gibt viele verschiedene Symbole, welche räumlich viel Platz benötigen.
- Kardinalität nicht sofort am Ende sichtbar: Man muss oft die Beziehung (Raute) lesen, statt die Kardinalität direkt am Linienende zu sehen.
- Schlecht skalierbar: Bei vielen Entitäten/Beziehungen wird das Diagramm sehr “breit” und schwer auf einer Seite darstellbar.
In der Folge entstanden eine Reihe von Alternativ-Notationen, die diese Probleme adressieren wollten. Die Information-Engineering-(IE)-Notation ist eine der bekanntesten davon und hat sich in der Praxis durchgesetzt. Sie ist heute der Standard in vielen Unternehmen und wird häufig in der Datenmodellierung verwendet.
Entität und Attribute
Abschnitt betitelt „Entität und Attribute“Auch im IE-Modell werden Entitäten als Rechtecke dargestellt. Allerdings sind die Rechtecke in der IE-Notation oft etwas schlichter gehalten, ohne die zusätzlichen Linien für Attribute wie in der Chen-Notation. In der IE-Notation werden Attribute innerhalb des Rechtecks der Entität aufgelistet, anstatt sie als separate Ovale darzustellen.
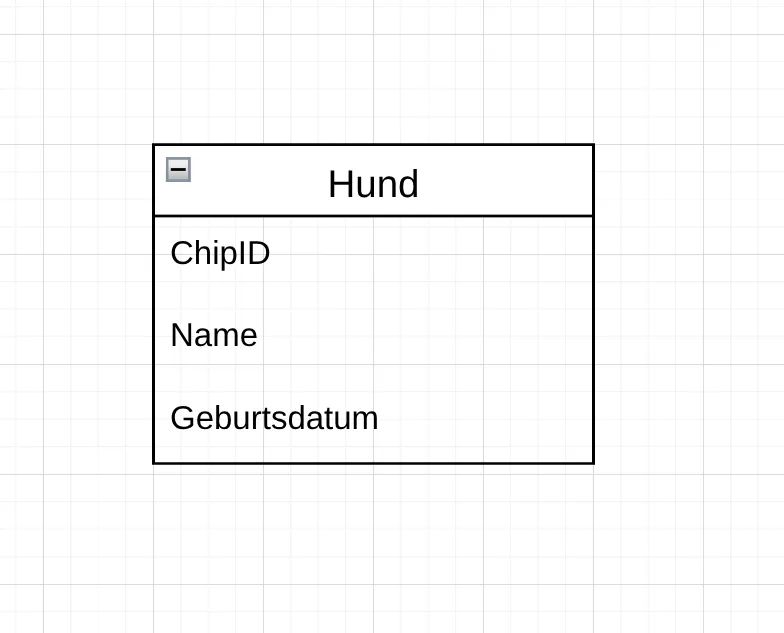
Das sorgt für eine kompaktere Darstellung und erleichtert das Lesen des Modells.
Beziehungen und Kardinalitäten
Abschnitt betitelt „Beziehungen und Kardinalitäten“Die Krähenfuss-Notation verwendet Linien, um Beziehungen zwischen Entitäten darzustellen. Die Kardinalitäten werden direkt an den Linienenden durch spezielle Symbole angezeigt.
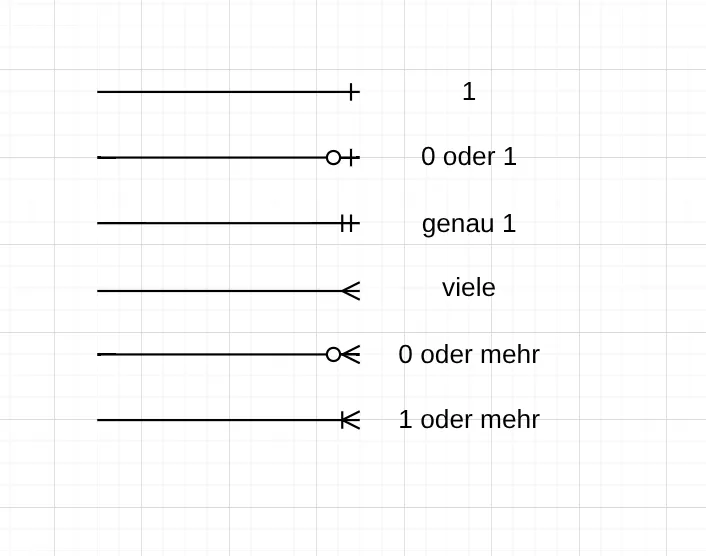
Durch diese Darstellung sind die Kardinalitäten sofort am Linienende sichtbar, was das Verständnis der Beziehungen erleichtert. Durch die Form der “viele” Kardinalität erhält die Notation ihren Namen “Krähenfuss”.

Im obigen Beispiel sind diese Kardinalitäten sofort erkennbar:
-
Ein Student kann sich für viele Kurse anmelden. Auch für gar keinen. Umgekehrt hat jeder Kurs hat viele Studenten, aber mindestens einen.
-
Ein Kunde kann viele Bestellungen aufgeben, es gibt allerdings auch Kunden ohne Bestellungen. Jede Bestellung gehört aber genau einem Kunden.
-
Ein Mitarbeiter arbeitet in genau einer Abteilung. Eine Abteilung hat viele Mitarbeiter, aber mindestens einen.
Zur Klarstellung von Beziehungen können auch Beziehungsnamen hinzugefügt werden, ähnlich wie in der Chen-Notation.
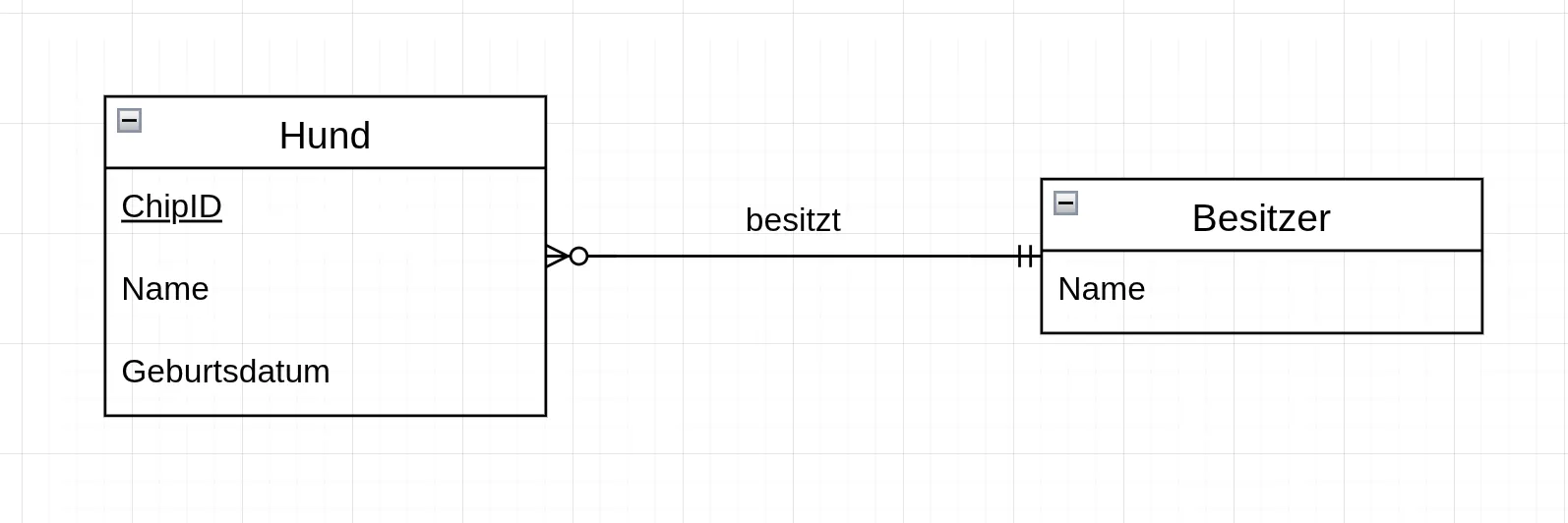
Assoziative Entitäten
Abschnitt betitelt „Assoziative Entitäten“In der (reinen) Krähenfuss-Notation gibt es keine Möglichkeit, Beziehungen mit Attributen darzustellen. Stattdessen wird in solchen Fällen eine assoziative Entität eingeführt. Diese assoziative Entität repräsentiert die Beziehung selbst als eigenständige Entität mit eigenen Attributen.
Generalisierung/Spezialisierung
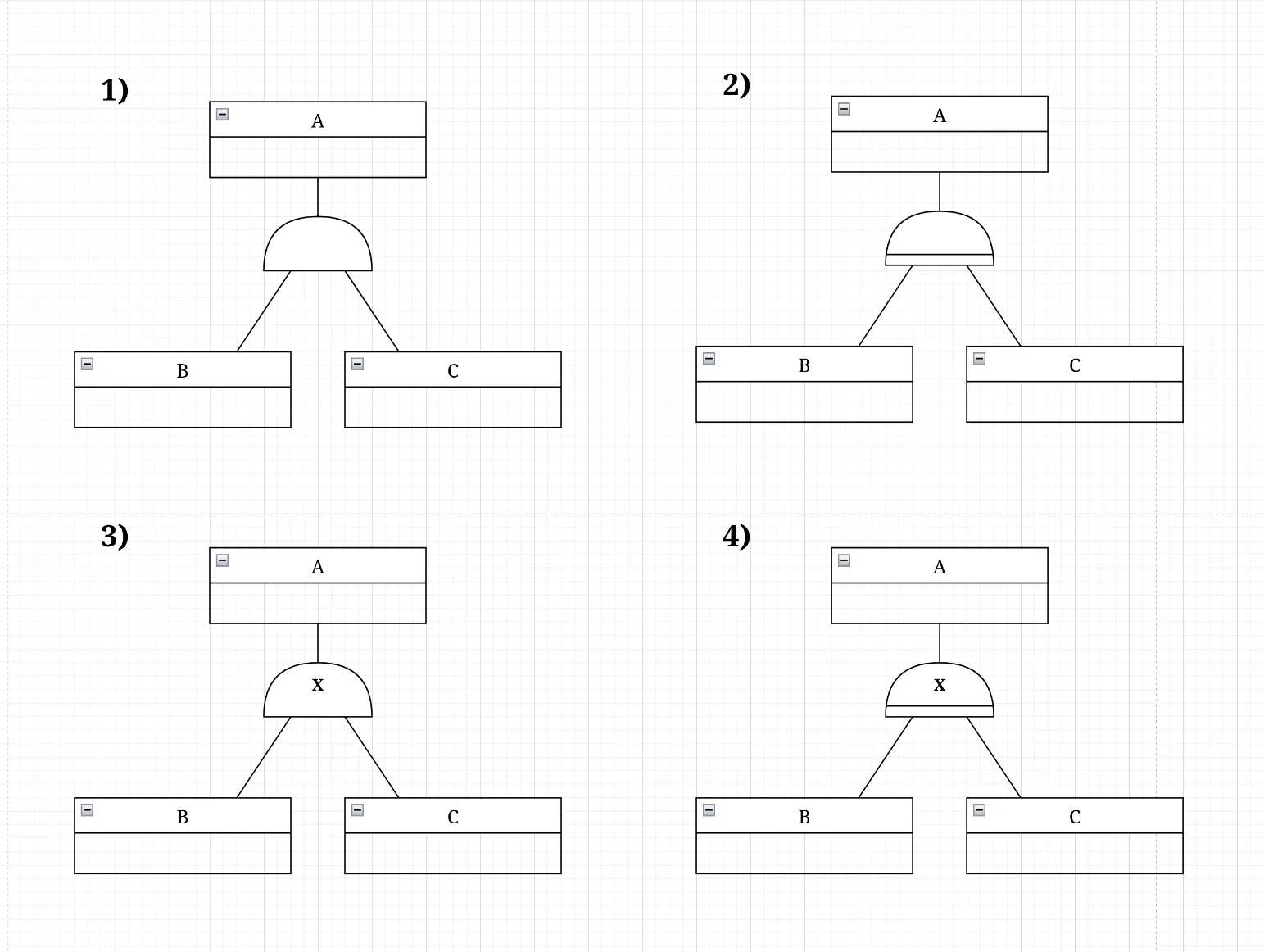
Abschnitt betitelt „Generalisierung/Spezialisierung“In der Krähenfuss-Notation wird die Generalisierung/Spezialisierung ähnlich wie in der Chen-Notation dargestellt, jedoch ohne die Raute. Stattdessen wird ein Dreieck verwendet und manchmal auch ein Halbkreis verwendet, welche die Generalisierungs-/Spezialisierungsbeziehung symbolisieren. Das Dreieck, bzw. der Halbkreis wird mit Linien zu den beteiligten Entity-Typen verbunden, wobei die Spitze des Dreiecks (oder die Mitte des Kreisbogen) auf den allgemeineren Entity-Typ zeigt.
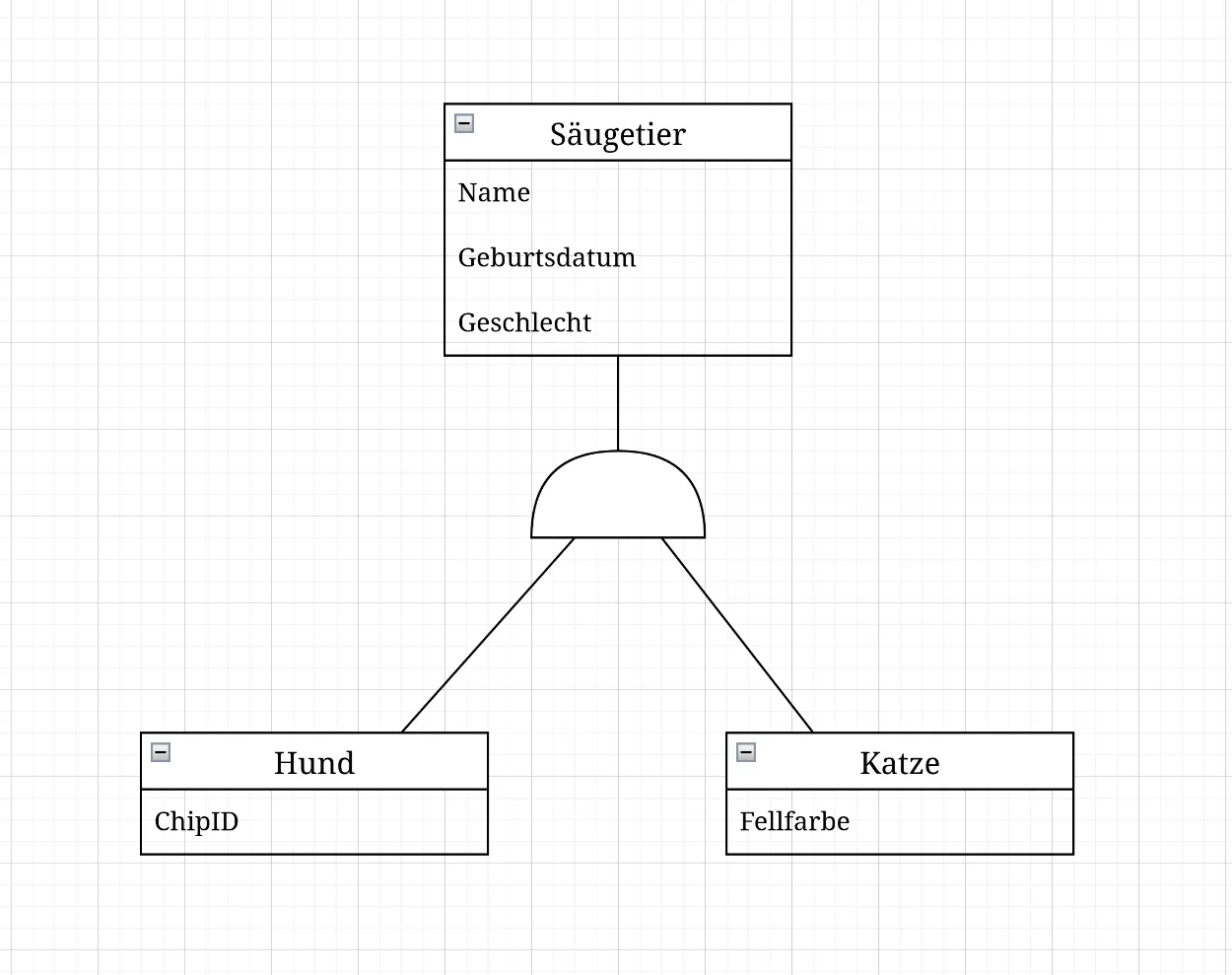
Allerdings ist diese Notation nicht so weit verbreitet wie die Chen-Notation, und es gibt weniger standardisierte Symbole für die Darstellung von Generalisierungen/Spezialisierungen.
Es gibt ebenfalls Varianten, welche die Teilmengen der Spezialisierungen kennzeichnen (disjunkt vs. überlappend) und ob die Generalisierung vollständig oder partiell ist. Diese werden jedoch nicht immer verwendet.
-
Partiell: Nicht jedes Exemplar der Oberklasse muss einer Unterklasse angehören. Das obige Bild ist ein Beispiel für eine partielle Generalisierung. Neben Hunden und Katzen könnte es also noch andere Säugetiere geben (z. B. Kaninchen, Meerschweinchen, Hamster, …).
-
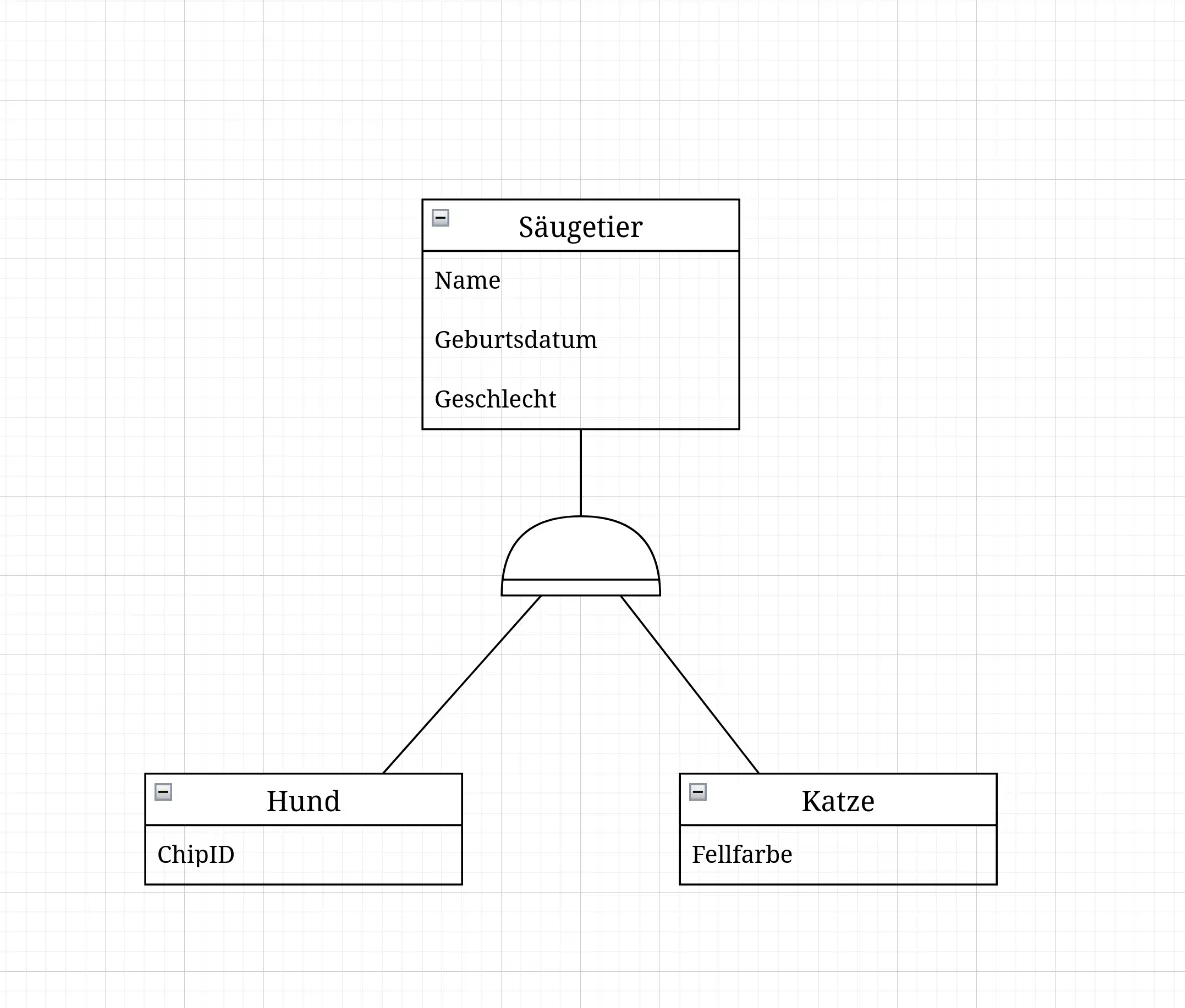
Total: Jedes Exemplar der Oberklasse muss mindestens einer Unterklasse angehören. Hier wird ein zusätzlicher Querstrich am Dreieck oder den Halbkreis angebracht. In dem Beispiel unten bedeutet das, dass es keine anderen Säugetiere außer Hunden und Katzen in diesem Modell gibt. Das ist alles: Hunde und Katzen sind die einzigen Säugetiere, die es gibt! Punkt.
-
Überlappend: Die Unterklassen können gleichzeitig existieren. Ein Exemplar der Oberklasse kann mehreren Unterklassen angehören. In dem Beispiel unten bedeutet das, dass ein Säugetier sowohl ein Hund als auch eine Katze sein kann (z. B. ein “Katzenhund”… wenn so etwas gäbe würde).
-
Disjunkt: Die Unterklassen sind ausschließlich. Ein Exemplar der Oberklasse kann nur einer Unterklasse angehören. In dem Beispiel unten bedeutet das, dass ein Säugetier entweder ein Hund oder eine Katze ist, aber nicht beides gleichzeitig. Dafür wird in der Regel ein Kreuz in das Dreieck oder den Halbkreis gezeichnet.
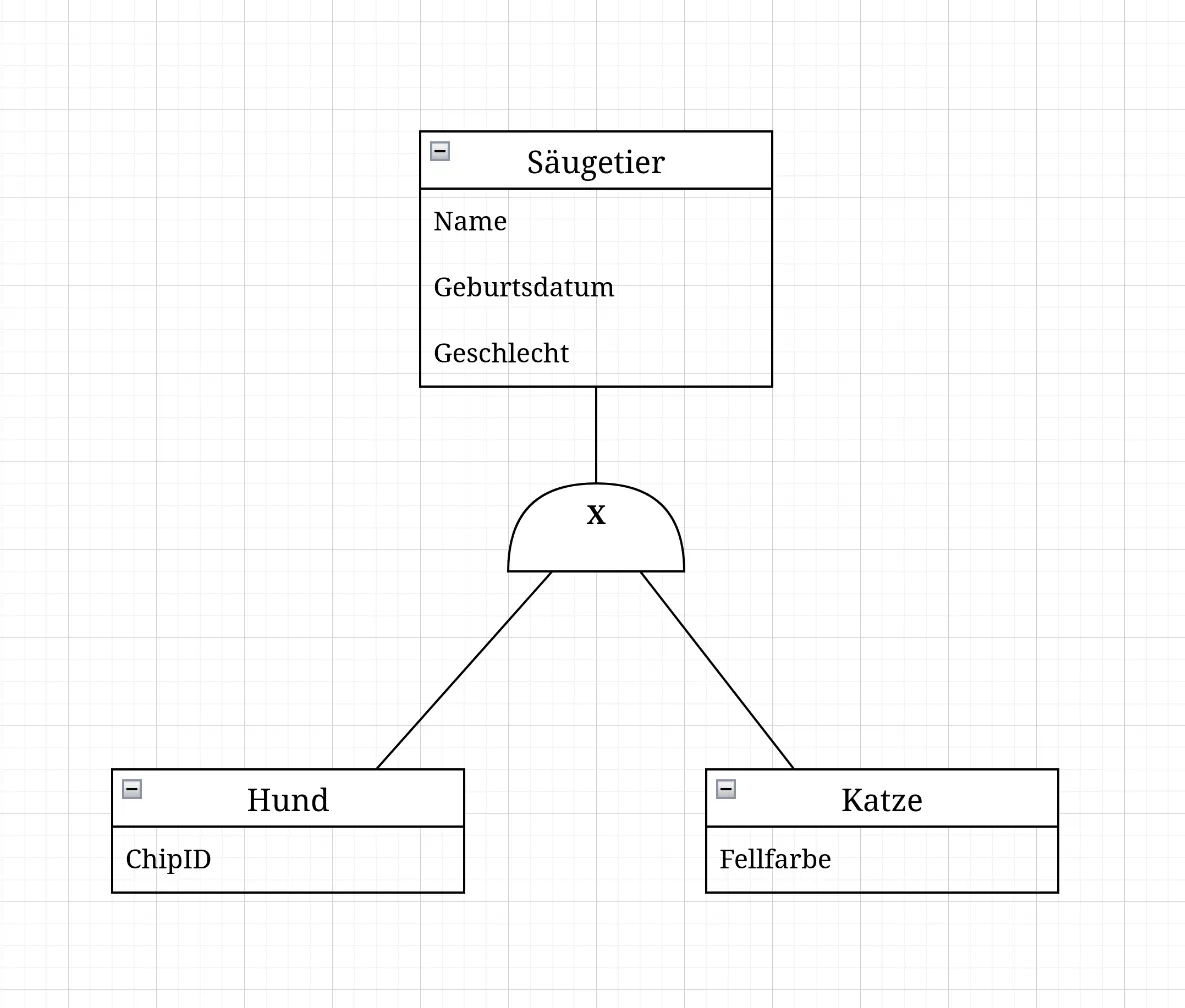
Zusammengefasst:
Hier sind die Schritte zur Erstellung des ER-Diagramms in der Krähenfuss-Notation konzeptionell identisch zu denen in der Chen-Notation. Der einzige Unterschied liegt in der grafischen Darstellung.
Lernergebnisse: Was Sie nach diesem Kapitel können sollten
Abschnitt betitelt „Lernergebnisse: Was Sie nach diesem Kapitel können sollten“Nach Abschluss dieses Kapitels sollten Schülerinnen und Schüler in der Lage sein:
- Nennen: die Bestandteile eines ER-Modells (Entitäten, Attribute, Beziehungen, Kardinalitäten) nennen.
- Beschreiben: die Schritte der Datenmodellierung und die Abstraktionsmechanismen (Klassifikation, Aggregation, Generalisierung) beschreiben.
- Anwenden: ein gegebenes Realweltszenario in ein ER-Diagramm in Chen- bzw. Krähenfuß-Notation überführen.
- Vergleichen: die Chen-Notation und die Information-Engineering-(Krähenfuß-)Notation gegenüberstellen.
- Entwerfen: ein konzeptuelles Datenmodell für eine gegebene Aufgabenstellung selbstständig entwerfen.