4. Relationenmodell
Das relationale Datenbankmodell
Abschnitt betitelt „Das relationale Datenbankmodell“Das relationale Datenmodell wurde 1970 vom Mathematiker E. F. Codd entwickelt und mit Hilfe der Mengentheorie beschrieben. Es bildet bis heute die Grundlage für relationale Datenbanken. Datenbanksysteme, die auf diesem Modell beruhen, sind nach wie vor die am weitesten verbreitete Form von Datenbanksystemen.
Für relationale Datenbanken wurde die Datenmanipulationssprache SQL entwickelt, die sich international als Standard durchgesetzt hat.
Im relationalen Modell besteht eine Datenbank aus einer Menge von Relationen, in denen logisch zusammengehörige Daten gespeichert werden.
Relation
Abschnitt betitelt „Relation“In einer relationalen Datenbank bezeichnet der Begriff Relation eine Menge von Tupeln (Datensätzen). Eine Relation lässt sich als Tabelle mit Spalten und Zeilen darstellen.
Sowohl Entitäten als auch Beziehungen aus dem Entity-Relationship-Modell werden im relationalen Modell als Relationen abgebildet. Datenbanktechnisch meint “Relation” also nicht die Verknüpfung zwischen Tabellen, sondern die Tabelle selbst, in der die Daten gespeichert sind. Diese Daten repräsentieren die Informationen, die in der Datenbank verwaltet werden.
Eine Relation ist gekennzeichnet durch:
- einen eindeutigen Namen, z. B.
Kunde - mehrere Attribute (Spalten)
- keine bis beliebig viele Tupel (Tabellenzeilen bzw. Datensätze)
- genau einen Wert pro Attribut in einem Tupel (Tabellenzelle)
- einen Primärschlüssel, bestehend aus einem oder mehreren Attributen
- dieser identifiziert jedes Tupel eindeutig
Attribute und Tupel
Abschnitt betitelt „Attribute und Tupel“Eine Tabelle in einer relationalen Datenbank besteht aus Spalten und Zeilen. Die Spalten werden Attribute oder auch Felder genannt, die Zeilen werden als Tupel oder Datensätze bezeichnet.

Der Aufbau aller Tupel in einer Tabelle ist gleich.
Der Aufbau einer Relation wird Struktur oder auch Schema der Tabelle genannt. Die Gesamtheit aller Relationenschemata einer Datenbank heißt Schema der Datenbank.
Verschiedene Datenbanksysteme verwenden leicht unterschiedliche Formate für Relationen. Diese Unterschiede hängen unter anderem ab von:
- den Regeln für die Namensgebung von Relationen und Attributen
- den verfügbaren Datentypen für Attribute.
Jedem Datentyp sind bestimmte Eigenschaften zugeordnet, die festlegen, welche Art von Werten in einem Attribut gespeichert werden können (z. B. Ganzzahlen, Zeichenketten, Datumswerte). Das bedeutet, dass jeder Eintrag in einem Attribut den definierten Datentyp erfüllen muss und damit auch Speicherplatz beansprucht, der für diesen Datentyp vorgesehen ist.
NULL-Werte
Abschnitt betitelt „NULL-Werte“Ist für ein Attribut kein Wert eingetragen, kann ein sogenannter NULL-Wert verwendet werden. Ein NULL-Wert gehört zu keinem Datentyp und darf nicht mit dem numerischen Wert 0 verwechselt werden.
Ein NULL-Wert ist ein symbolischer Platzhalter, der angibt, dass zu diesem Attribut in einem Tupel kein Wert vorhanden ist. Da es sich nur um ein Symbol handelt, kann ein NULL-Wert mit keinem anderen Wert verglichen werden - auch nicht mit einem anderen NULL-Wert.
Ein leerer Wert ist davon zu unterscheiden: Er entsteht zum Beispiel, wenn ein vorhandener Attributwert gelöscht wird. So ist ein leerer Wert in einem Textattribut eine leere Zeichenkette (""), in einem numerischen Attribut der Wert 0.
Schlüssel
Abschnitt betitelt „Schlüssel“In einer Relation dürfen aufgrund der Mengendefinition keine zwei identischen Tupel vorkommen. Das bedeutet: Jedes Tupel lässt sich durch einen oder mehrere Attributwerte (im Extremfall durch alle) eindeutig identifizieren.
Die Menge der Attribute, mit denen ein Tupel eindeutig bestimmt werden kann, heißt Schlüsselkandidat. Für Schlüssel gilt die Minimalitätsanforderung: Ein Schlüssel soll so kurz wie möglich sein; keine Teilmenge der verwendeten Attribute darf selbst bereits ein Schlüssel sein.
Primärschlüssel
Abschnitt betitelt „Primärschlüssel“Aus den vorhandenen Schlüsselkandidaten wird genau einer als Primärschlüssel (Hauptschlüssel) ausgewählt. In einem Beispiel mit der Relation Kunde könnte das Attribut KundenNr der Primärschlüssel sein, weil es der “kürzeste” mögliche Schlüssel ist (nur ein Attribut). In vielen Darstellungen wird der Primärschlüssel durch Unterstreichen gekennzeichnet (bsp. ER-Diagramme in Chen- oder Krähenfuss-notation).
Um alle Tupel einer Relation eindeutig zu unterscheiden, kann auch ein zusätzliches Attribut eingeführt werden, das die Datensätze einfach durchnummeriert. Dieses Attribut kann dann als Primärschlüssel dienen. Man spricht dann von einem surrogate key.
Wichtige Punkte zum Primärschlüssel:
- Eine Relation besitzt genau einen Primärschlüssel.
- Der Primärschlüssel kann aus einem einzelnen Attribut oder aus einer Attributkombination bestehen.
- Das Attribut bzw. die Attributkombination, die als Primärschlüssel verwendet wird, heißt identifizierendes Attribut (bzw. identifizierende Attribute).
- Alle Attribute bzw. Attributkombinationen, die eindeutige Werte liefern, sind Schlüsselkandidaten - aber nur einer davon wird tatsächlich als Primärschlüssel festgelegt.
- Falls eine Tabelle kein natürlich eindeutiges Datenfeld besitzt, wird häufig eine künstliche eindeutige ID vergeben, z. B. eine ID für die Relation
Kunden.
In Notationen kann ein Primärschlüssel z. B. gekennzeichnet werden durch:
- Unterstreichung des Attributnamens
- die Abkürzung PK oder
- ein nachgestelltes Zeichen wie
*

Fremdschlüssel
Abschnitt betitelt „Fremdschlüssel“Ein Fremdschlüssel ist ein Attribut in einer Relation, das auf ein Schlüsselfeld einer anderen Relation verweist und damit eine Beziehung zwischen den beiden Relationen herstellt.
In Notationen kann ein Fremdschlüssel z. B. gekennzeichnet werden durch:
- die Abkürzung FK oder
- ein nachgestelltes Zeichen wie
#

Sekundärschlüssel
Abschnitt betitelt „Sekundärschlüssel“Der Begriff Sekundärschlüssel ist nicht eindeutig definiert.
Häufig wird darunter ein alternativer Suchschlüssel verstanden, der neben dem Primärschlüssel als zusätzliches Suchkriterium dient. Er kann verwendet werden, um einen oder mehrere Datensätze zu finden. Wie jeder Suchschlüssel kann auch ein Sekundärschlüssel aus einem oder mehreren Attributen bestehen.
Im Unterschied zum Primärschlüssel ist ein Sekundärschlüssel in dieser Definition nicht zwingend eindeutig. Eine Suche mit einem Sekundärschlüssel kann daher mehrere Datensätze als Ergebnis liefern.
Eine andere Sichtweise setzt Sekundärschlüssel mit einem Alternativschlüssel gleich, also mit einem weiteren Schlüsselkandidaten. In diesem Fall ist ein Sekundärschlüssel also ebenfalls eindeutig, wird aber nicht als Primärschlüssel verwendet.
Gemein ist aber, dass mit einem Sekundärschlüssel ebenfalls, so wie mit dem Primärschlüssel, auf Datensätze zugegriffen werden kann.
Oft werden die Tupel einer Relation in einer anderen Reihenfolge benötigt, als sie ursprünglich gespeichert wurden - etwa sortiert nach Postleitzahlen. Dazu müsste die gesamte Relation nach diesem Attribut sortiert werden. Bei einer großen Anzahl von Tupeln kann das sehr viel Zeit beanspruchen.
Um den Zugriff auf die Daten zu beschleunigen, können zusätzlich zum Primärschlüssel weitere Indizes angelegt werden. Diese werden auch Sekundärindizes bzw. auch Sekundärschlüssel genannt.
Werden mehrere Indizes verwendet, entsteht beim Einfügen vieler Datensätze ein hoher Aufwand, weil alle Indizes laufend mitaktualisiert werden müssen. In solchen Fällen ist es oft sinnvoll, die Indizes erst nach dem Befüllen der Tabelle zu erzeugen bzw. zu aktualisieren.
Ein Index ist vergleichbar mit einem Glossar am Ende eines Buches: Dort sind die Begriffe alphabetisch sortiert mit Seitenzahlen versehen, damit man die gewünschten Informationen schnell findet, ohne das ganze Buch durchsuchen zu müssen.
Transformation vom ER-Modell zum Relationenmodell
Abschnitt betitelt „Transformation vom ER-Modell zum Relationenmodell“Die Transformation eines ER-Modells in ein relationales Modell erfolgt durch die Abbildung von Entitäten, Attributen und Beziehungen in Relationen (Tabellen). Dabei werden die folgenden Schritte beachtet:
-
Entitätstypen in Relationen umwandeln: Jeder Entitätstyp im ER-Modell wird zu einer eigenen Relation (Tabelle). Die Attribute der Entität werden zu den Attributen der Relation.
-
Primärschlüssel festlegen: Für jede Relation wird ein Primärschlüssel definiert, der die Tupel eindeutig identifiziert. Dies kann ein einzelnes Attribut oder eine Kombination von Attributen sein.
-
1:1 Beziehungen abbilden: Bei 1:1 Beziehungen kann der Primärschlüssel einer der beteiligten Relationen als Fremdschlüssel in die andere Relation übernommen werden.
 Abb. 7.4: Bei einer 1-1 Relation wird der Primärschlüssel einer Relation als Fremdschlüssel in die andere Relation übernommen.
Abb. 7.4: Bei einer 1-1 Relation wird der Primärschlüssel einer Relation als Fremdschlüssel in die andere Relation übernommen. -
1:n Beziehungen abbilden: Bei 1:n Beziehungen wird der Primärschlüssel der “1”-Seite als Fremdschlüssel in die “n”-Seite übernommen.
 Abb. 7.5: Bei einer 1-n Relation wird der Primärschlüssel der '1'-Seite als Fremdschlüssel in die 'n'-Seite übernommen.
Abb. 7.5: Bei einer 1-n Relation wird der Primärschlüssel der '1'-Seite als Fremdschlüssel in die 'n'-Seite übernommen. -
n:m Beziehungen abbilden: Für n:m Beziehungen wird eine neue Relation (Zwischentabelle, Junktionstabelle oder Pivot-Tabelle) erstellt, die die Primärschlüssel der beiden beteiligten Relationen als Fremdschlüssel enthält. Diese Fremdschlüssel bilden zusammen den Primärschlüssel der neuen Relation.
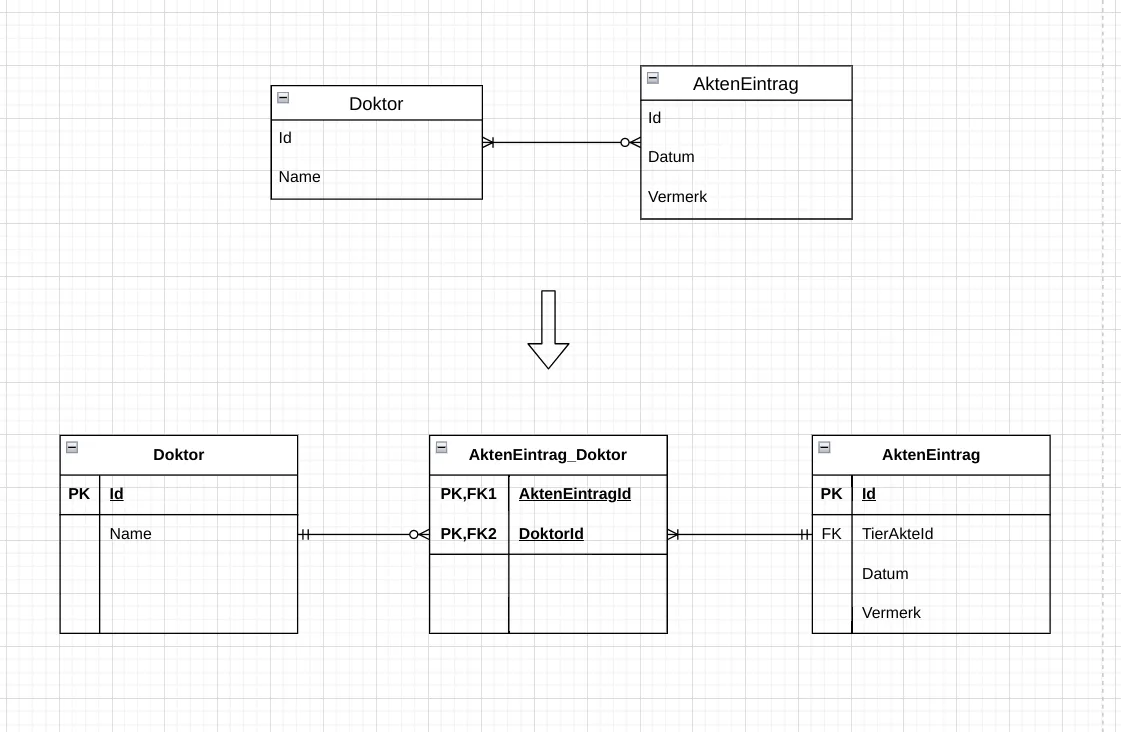 Abb. 7.6: Für eine m-n Relation wird eine neue Relation erstellt, die die Primärschlüssel der beteiligten Relationen als Fremdschlüssel enthält.
Abb. 7.6: Für eine m-n Relation wird eine neue Relation erstellt, die die Primärschlüssel der beteiligten Relationen als Fremdschlüssel enthält. -
Generalisierungen: Der Entitätstyp der Generalisierung kann entweder a) vollkommen in die Superklasse integriert werden, b) als jeweils komplett eigenständige Relation abgebildet werden oder c) als separate Relation mit einem Fremdschlüssel zur Superklasse dargestellt werden.
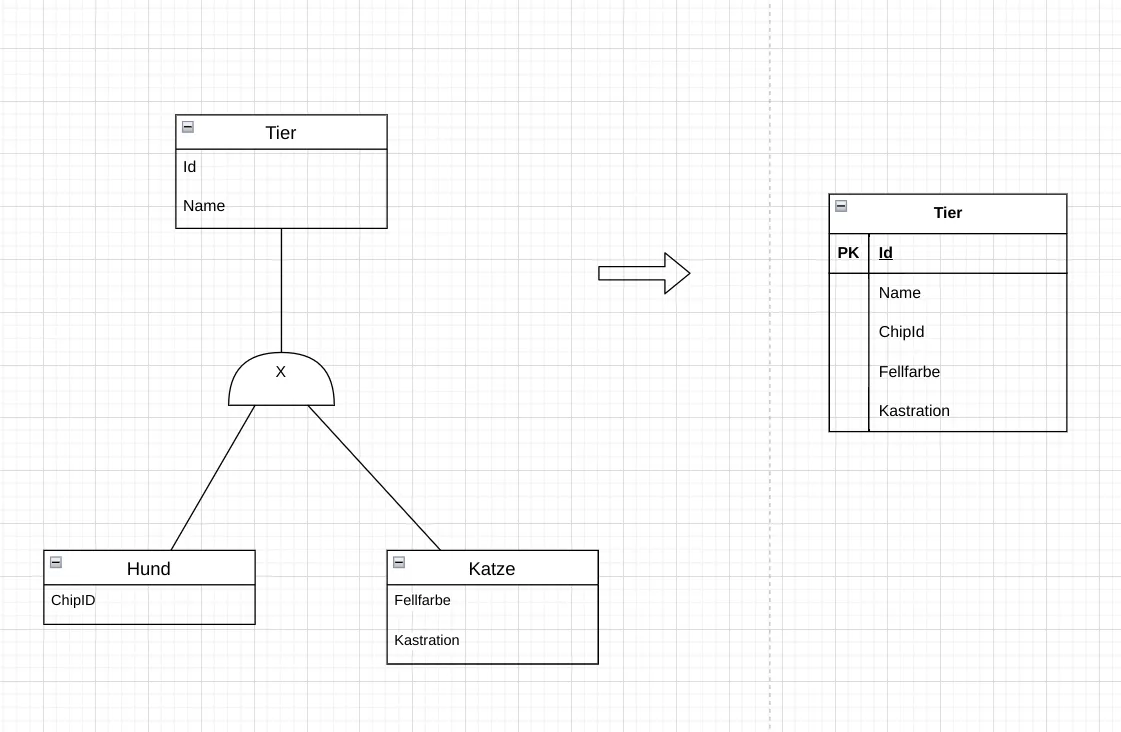 Abb. 7.7: Abbildung einer Generalisierung im Relationenmodell: erstellen einer alles umfassenden Superklasse. Die Spezialisierungen werden nicht als eigene Relationen abgebildet. Die Superklasse enthält alle Attribute aller Spezialisierungen. Wo diese nicht gesetzt sind, werden NULL-Werte eingetragen.
Abb. 7.7: Abbildung einer Generalisierung im Relationenmodell: erstellen einer alles umfassenden Superklasse. Die Spezialisierungen werden nicht als eigene Relationen abgebildet. Die Superklasse enthält alle Attribute aller Spezialisierungen. Wo diese nicht gesetzt sind, werden NULL-Werte eingetragen.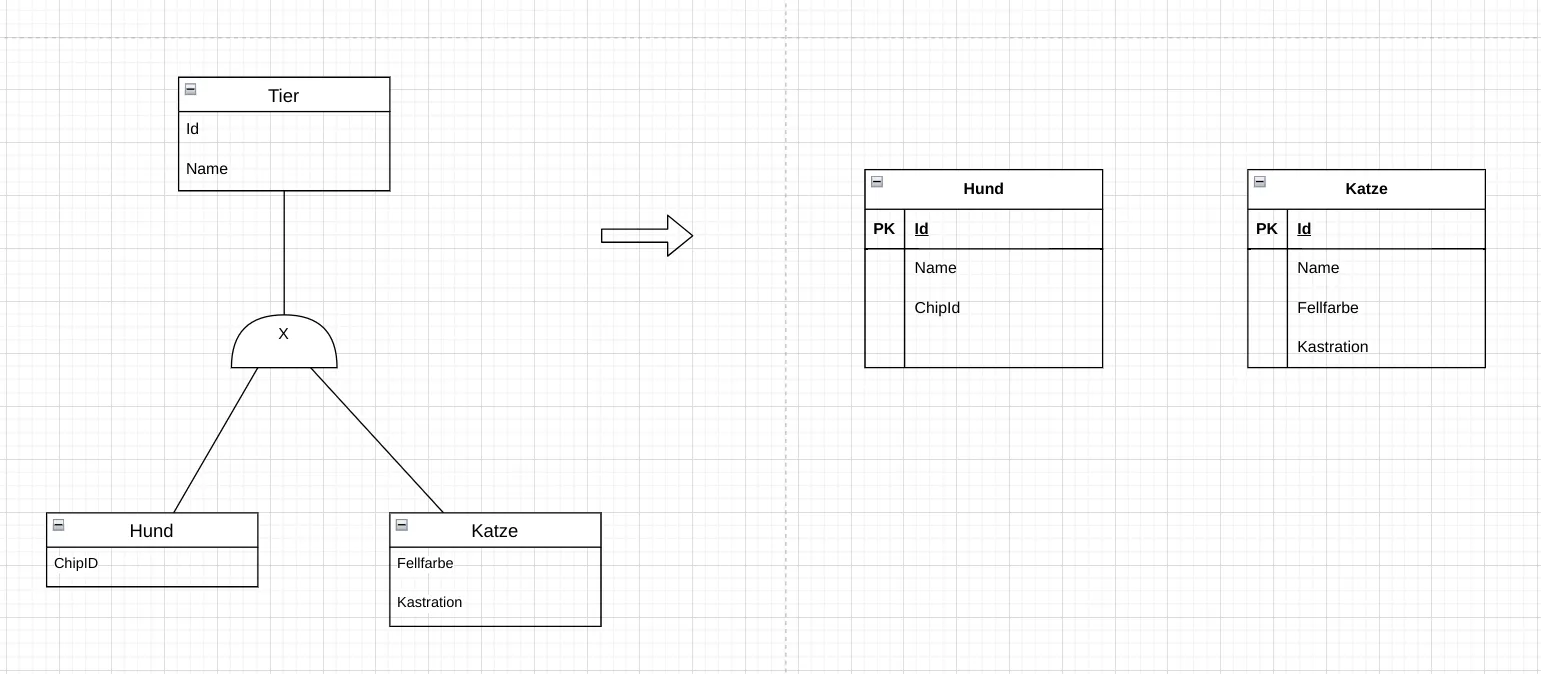 Abb. 7.8: Abbildung einer Generalisierung im Relationenmodell: komplett eigenständige Relationen. Die Superklasse wird nicht als eigene Relation abgebildet, sie existiert nur im logischen ER-Modell. Es gibt dann auch keine Information über die Zugehörigkeit zu einer Spezialisierung. Alle Attribute der Superklasse werden in jeder Spezialisierung wiederholt.
Abb. 7.8: Abbildung einer Generalisierung im Relationenmodell: komplett eigenständige Relationen. Die Superklasse wird nicht als eigene Relation abgebildet, sie existiert nur im logischen ER-Modell. Es gibt dann auch keine Information über die Zugehörigkeit zu einer Spezialisierung. Alle Attribute der Superklasse werden in jeder Spezialisierung wiederholt.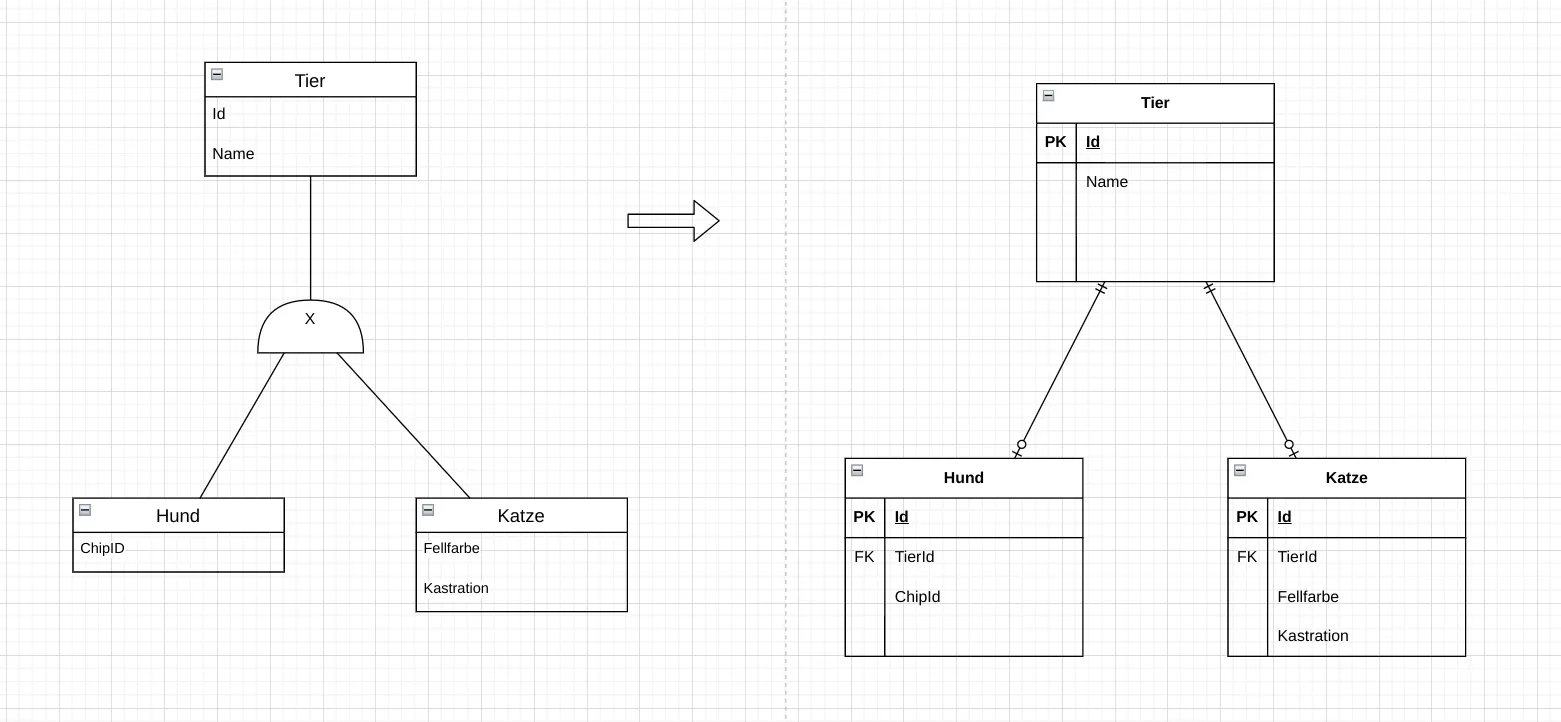 Abb. 7.9: Abbildung einer Generalisierung im Relationenmodell: Eine Superklasse und in den Spezialisierungen mit Fremdschlüssel. Das ist die naheliegendste Abbildung. Die Superklasse wird als eigene Relation abgebildet, die Spezialisierungen ebenfalls. In den Spezialisierungen wird der Primärschlüssel der Superklasse als Fremdschlüssel übernommen. Allerdings wird beim Zugriff dann mehr Aufwand betrieben, da die Daten aus mehreren Relationen zusammengeführt werden müssen (JOIN).
Abb. 7.9: Abbildung einer Generalisierung im Relationenmodell: Eine Superklasse und in den Spezialisierungen mit Fremdschlüssel. Das ist die naheliegendste Abbildung. Die Superklasse wird als eigene Relation abgebildet, die Spezialisierungen ebenfalls. In den Spezialisierungen wird der Primärschlüssel der Superklasse als Fremdschlüssel übernommen. Allerdings wird beim Zugriff dann mehr Aufwand betrieben, da die Daten aus mehreren Relationen zusammengeführt werden müssen (JOIN).Welche der drei Ansätze gewählt wird, hängt von den Anforderungen an die Datenbank ab. Es kann auch innerhalb ein und derselben Umsetzeung je nach Generalisierung unterschiedlich gehandhabt werden.
Die Transformation vom ER-Modell zum Relationenmodell ist ein wichtiger Schritt bei der Entwicklung relationaler Datenbanken. Sie stellt sicher, dass die logische Struktur der Datenbank den Anforderungen der Anwendung entspricht und eine effiziente Speicherung und Abfrage der Daten ermöglicht.
Aus dem relationalen Modell lassen sich dann die physischen Datenbankstrukturen ableiten, die in einem konkreten Datenbanksystem implementiert werden.
Textbeschreibung des Datenmodells
Abschnitt betitelt „Textbeschreibung des Datenmodells“Eine relationale Datenbank kann auch textuell beschrieben werden. Dabei wird für jede Relation der Name der Relation, die Attribute mit Angabe von Datentypen und Einschränkungen sowie der Primär- und Fremdschlüssel angegeben. Die Primärschlüssel und Fremdschlüssel werden dabei explizit gekennzeichnet. Bei den Primärschlüsseln wird oft die Abkürzung PK verwendet, bei den Fremdschlüsseln die Abkürzung FK. Alternativ können auch andere Kennzeichnungen verwendet werden, wie z. B. Unterstreichungen oder spezielle Symbole wie Pfeile in die Ursprungstabelle eines Fremdschlüssels.
Für diese Notation gibt es keine festen Regeln. Wichtig ist, dass die Beschreibung klar und verständlich ist und alle notwendigen Informationen enthält, um die Struktur der Datenbank zu verstehen.
Abschließender Hinweis
Abschnitt betitelt „Abschließender Hinweis“Lernergebnisse: Was Sie nach diesem Kapitel können sollten
Abschnitt betitelt „Lernergebnisse: Was Sie nach diesem Kapitel können sollten“Nach Abschluss dieses Kapitels sollten Schülerinnen und Schüler in der Lage sein:
- Definieren: die Begriffe Relation, Attribut, Tupel, Primär- und Fremdschlüssel definieren.
- Beschreiben: die Bedeutung von NULL-Werten und Schlüsseln im Relationenmodell beschreiben.
- Erklären: erklären, wie Beziehungen über Fremdschlüssel abgebildet werden.
- Anwenden: ein ER-Modell nach den Transformationsregeln in ein Relationenmodell überführen.
- Beurteilen: beurteilen, welche Attribute sich als Schlüsselkandidaten eignen.