1. Grundlagen
Grundlagen von Datenbanksystemen
Abschnitt betitelt „Grundlagen von Datenbanksystemen“Entwicklung der Datenbanken
Abschnitt betitelt „Entwicklung der Datenbanken“Datenbanken sind das Rückgrat vieler Computeranwendungen. Immer wenn Arbeitsabläufe digital ablaufen, müssen große Datenmengen zuverlässig gespeichert, schnell gefunden und sicher verändert werden. Das gilt für die Personalverwaltung, die Lagerverwaltung sowie das Bestell- und Rechnungswesen aber auch in Computerspielen. In größeren Unternehmen übernimmt das oft ein ERP-System (Enterprise Resource Planning), das viele Geschäftsprozesse bündelt und auf eine gemeinsame Datenbasis zugreift. Auch im Web spielen Datenbanken eine zentrale Rolle - etwa bei Online-Shops, Buchungssystemen, Social-Media-Plattformen oder Nachschlagewerken wie Wikipedia.
Kurz: überall fallen Daten an und werden verarbeitet, also gespeichert, verknüpft und gelesen.
Speichert man Daten nur in einfachen Dateien (z. B. CSV, Textdateien oder selbst gebastelte Formate), treten typische Probleme auf:
-
Redundanzen: Die gleichen Informationen werden mehrfach gespeichert (z. B. die Adresse eines Kunden in mehreren Dateien). Änderungen sind aufwendig, weil man an mehreren Stellen nachbessern muss.
-
Inkonsistenzen: Durch Redundanzen entstehen schnell Widersprüche. Wenn eine Adresse nur in einer Datei aktualisiert wird, stimmen die anderen Kopien nicht mehr.
-
Eingeschränkter Mehrbenutzerbetrieb: Wird eine Datei bearbeitet, wird sie häufig komplett gesperrt. Währenddessen können andere nicht gleichzeitig mit denselben Daten arbeiten - das bremst Teams aus.
-
Datenschutzprobleme: In Dateisystemen ist es schwierig, fein zu steuern, wer welche Felder sehen oder ändern darf. Man braucht Zusatzlösungen (Lesesperren, Verschlüsselung), die leicht fehleranfällig sind.
-
Fehlende Datenunabhängigkeit: Programme müssen die genaue Dateistruktur kennen. Ändert sich diese Struktur, müssen alle Programme angepasst werden. Nutzen mehrere Anwendungen dieselben Dateien, braucht oft jede ihre eigene Datenverwaltung - der Wartungsaufwand explodiert.
Wie lösen das Datenbanksysteme besser?
-
Zentrale, konsistente Datenbasis: Alle Anwendungen greifen auf dieselben, aktuellen Daten zu. Regeln (z. B. “Kundennummer darf nicht doppelt vorkommen”) werden vom DBMS erzwungen.
-
Gleichzeitiges Arbeiten (Transaktionen): Mehrere Personen oder Dienste können parallel arbeiten, ohne sich gegenseitig die Daten kaputtzumachen. Änderungen werden entweder vollständig durchgeführt oder gar nicht - halbfertige Zustände werden vermieden.
-
Sicherheit und Rollen: Man kann genau festlegen, wer lesen, einfügen, ändern oder löschen darf - bis hinunter auf Tabellen- oder sogar Spaltenebene.
-
Performance: Durch Indizes findet das DBMS Daten sehr schnell, auch wenn Tabellen Millionen von Zeilen haben. Abfragen lassen sich mit SQL gezielt formulieren.
-
Backups und Wiederherstellung: Daten können regelmäßig gesichert und bei Problemen (z. B. Hardwarefehler) wiederhergestellt werden.
-
Datenunabhängigkeit: Die Art, wie Daten gespeichert sind, ist vom Programm, das darauf zugreift, relativ entkoppelt. Strukturanpassungen (neue Spalten, neue Tabellen) sind möglich, ohne jede beteiligte Anwendung neu zu schreiben.
Beispiele:
-
Online-Shop: Tabellen für Produkte, Kunden, Bestellungen, Zahlungen. Beim Checkout prüft das DBMS, ob der Lagerstand reicht, und sperrt den Datensatz kurzzeitig, damit nicht zwei Personen das letzte Stück gleichzeitig kaufen.
-
Schule/HTL: Tabellen für Schüler und Schülerinnen, Lehrkräfte, Fächer, Stundenpläne, Noten. Rollen legen fest, dass Lehrkräfte Noten eintragen dürfen, Schüler und Schülerinnen sie aber nur lesen können.
Datenbanksysteme (DBS) wurden entwickelt, um typische Datei-Probleme wie Redundanzen, Inkonsistenzen und fehlenden Mehrbenutzerbetrieb zu lösen. In einem DBS liegen die Daten in einer Datenbank, und der Zugriff erfolgt ausschließlich über das Datenbankmanagementsystem (DBMS). Anwendungen sprechen also nicht mehr direkt die Dateien an, sondern stellen ihre Anfragen (z. B. in SQL) an das DBMS. Dadurch wird die enge Kopplung zwischen Daten und Programmen stark reduziert - Änderungen an der Datenstruktur machen Anwendungen viel seltener kaputt.
Bestandteile eines DBS
Abschnitt betitelt „Bestandteile eines DBS“-
Datenbank: Eine logisch zusammenhängende Sammlung von Daten zu einem Thema/Sachgebiet (z. B. “Shop”, “Schule”).
-
DBMS (Datenbankmanagementsystem): Die Software, die die Daten verwaltet und die Schnittstelle für Benutzer und Programme bereitstellt.
-
DBS (Datenbanksystem): Ein Datenbanksystem ist die Gesamtheit aus Datenbank, Datenbankmanagementsystem und den darauf zugreifenden Anwendungen.
Was übernimmt das DBMS konkret?
-
Zentrale Schnittstelle: Anwendungen formulieren Anfragen (SELECT, INSERT, UPDATE, DELETE - SQL Anweisungen). Das DBMS übersetzt und führt sie effizient aus.
-
Gleichzeitiges Arbeiten (Transaktionen): Mehrere Nutzer können parallel arbeiten, ohne sich gegenseitig Daten zu “zerschießen”. Änderungen sind “ganz oder gar nicht” (Atomarität).
-
Konsistenz & Regeln: Das DBMS erzwingt Constraints - engl. “Bedingungen” (z. B. eindeutige Kundennummern, Pflichtfelder, referentielle Integrität).
-
Zugriffsrechte & Datenschutz: Rollen und Rechte steuern genau, wer lesen, einfügen, ändern oder löschen darf – bis auf Tabellen- oder Spaltenebene.
-
Performance: Indizes, Caching und Optimierung sorgen dafür, dass auch große Datenmengen schnell gefunden werden.
-
Fehlertoleranz & Wiederherstellung: Bei Programm- oder Systemabstürzen helfen Transaktionsprotokolle (Logs), Backups und Recovery-Mechanismen, Daten korrekt wiederherzustellen.
-
Zentrale Steuerung & Kontrolle: Monitoring, Protokollierung und ein Datenkatalog (Metadaten) schaffen Übersicht und Nachvollziehbarkeit.
Beispiel (vereinfacht):
Ein Webshop speichert eine Bestellung als Transaktion: Warenkorb sichern, Lagerstand anpassen, Zahlung verbuchen. Stürzt das System zwischendurch ab, macht das DBMS die unvollständigen Änderungen automatisch rückgängig - es bleibt ein konsistenter Zustand.
Eigenschaften von Datenbankmanagementsystemen
Abschnitt betitelt „Eigenschaften von Datenbankmanagementsystemen“-
In Datenbanken sind Daten entsprechend ihren natürlichen Zusammenhängen gespeichert. Dabei ist es nicht entscheidend, in welcher Form die Daten in Anwendungen benötigt werden. Die Daten der Datenbank bilden einen Ausschnitt aus der realen Welt ab.
-
Auf die Daten einer Datenbank können viele Benutzer gleichzeitig zugreifen. Das Datenbank-managementsystem verwaltet sowohl die Daten als auch die Zugriffe darauf und sorgt dafür, dass dieselben Daten nicht gleichzeitig von mehreren Benutzern bearbeitet werden können. Auch wenn mehrere Anwendungen mit einer gemeinsamen Datenbasis arbeiten, so wird in den Anwendungsprogrammen meist nur auf einen Teil davon zugegriffen (auf eine Sicht auf die Datenbank).
Das Datenbankmanagementsystem ist die Software, welche die Datenbanken verwaltet.
Es ermöglicht:
- das Anlegen von Datenbanken,
- die Speicherung, Änderung und Löschung der Daten,
- das Abfragen der Datenbank,
- die Verwaltung von Benutzern, Zugriffen und Zugriffsrechten.
Um von Anwendungsprogrammen bzw. Benutzern auf die Daten einer Datenbank zugreifen zu können, stellt das DBS ein Sprachkonzept zur Verfügung. Bei relationalen DBS ist das meist die Datenbanksprache SQL (Structured Query Language - englisch: “strukturierte Abfragesprache”).
Geschichte der Datenbanken
Abschnitt betitelt „Geschichte der Datenbanken“Vom Dateisystem zur Datenbank: ein kurzer Überblick:
-
1950er: Magnetbänder (sequentielle Dateien) - Daten wurden nacheinander auf Bändern gespeichert. Das war günstig, aber langsam: Um einen bestimmten Datensatz zu finden, musste man oft das ganze Band “vorspulen”.
-
1960er: Magnetplatten (Direktzugriff, Mehrfachzugriff) - Mit Festplatten konnte man direkt auf die gesuchte Stelle springen. Das machte Suchen und paralleles Arbeiten deutlich schneller.
-
1970er (1. Generation): Hierarchisches Datenmodell - Daten wurden in Baumstrukturen organisiert (Eltern-Kind-Beziehungen). Schnell bei klaren Hierarchien, aber unflexibel bei Querverbindungen.
-
1970er: Netzwerkmodell (Weiterentwicklung) - Erlaubt viele-zu-viele-Beziehungen über Verknüpfungen (“Sets”). Flexibler als hierarchisch, jedoch komplex in der Anwendung.
-
1970er/1980er: Relationales Modell (Durchbruch in der Praxis) - Daten in Tabellen mit Schlüsseln und Beziehungen; Abfragen mit SQL. Starke Trennung von Daten und Anwendungen, hohe Flexibilität und Datenintegrität - bis heute der Standard in vielen Systemen.
-
Parallel dazu: Spalten- und dokumentenorientierte Ansätze:
-
Spaltenorientiert: Speichern Daten spaltenweise, was analytische Abfragen über viele Zeilen beschleunigt (Data Warehousing/Analytics).
-
Dokumentenorientiert: Speichern flexible Dokumente (z. B. JSON). Gut, wenn Datenschemata sich häufig ändern oder pro Datensatz variieren.
-
-
Anfang 1990er: Objektorientierte Datenbanken - Speichern Objekte direkt mit Attributen und Methoden. Passt gut zu objektorientierten Sprachen, setzte sich aber außerhalb von Spezialfällen weniger breit durch.
-
Mitte 1990er: Objektrelationale Datenbanken - Kombinieren relationales Fundament mit objektorientierten Ideen (Benutzerdefinierte Typen, Arrays, JSON/Geo-Typen). Ziel: das Beste aus beiden Welten.
-
Seit Mitte der 2000er: NoSQL-Trend (stark wachsend) - Sammelbegriff für Key-Value-, Dokument-, Wide-Column- und Graph-Datenbanken. Fokus auf Skalierbarkeit, hohe Verfügbarkeit und flexible Schemata – wichtig für Web-Scale-Anwendungen, Streaming und Big-Data-Szenarien.
Jede Stufe reagierte auf konkrete Anforderungen der Zeit: erst schnellerer Zugriff, dann flexiblere Modelle, schließlich massive Skalierung und Flexibilität. Heute wählt man je nach Use-Case: relational für starke Konsistenz und Struktur, NoSQL-Varianten für Flexibilität und riesige Datenmengen.
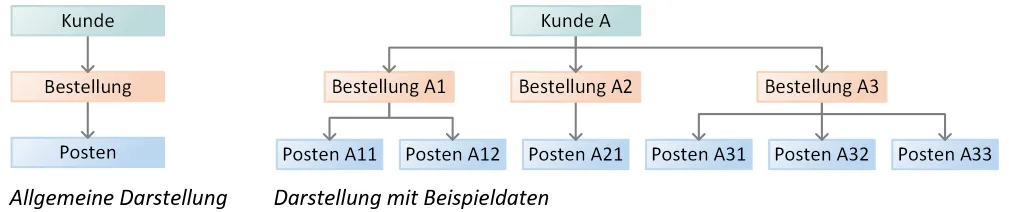
Hierarchische Datenbanken
Abschnitt betitelt „Hierarchische Datenbanken“Das hierarchische Datenmodell wurde entwickelt, um auch unterschiedlich lange Datensätze (also Datensätze mit unterschiedlich vielen/langen Feldern) effizient zu speichern. Dazu werden zusammengehörige Informationen in gleichartige Gruppen zerlegt; jede Gruppe bildet einen Knoten in einer Baumstruktur. So entsteht eine streng hierarchische Ordnung - vom Wurzelknoten (Root) über Elternknoten zu Kindknoten.
Grundprinzip (Vater-Sohn-Beziehung):
-
Jeder Kindknoten hat genau einen Elternknoten.
-
Ein Elternknoten kann mehrere Kinder besitzen.
-
Der Baum existiert nur mit seinem Wurzelknoten; ohne Root keine Struktur.
-
Die Bedeutung eines Datensatzes ergibt sich aus seinem Pfad von der Wurzel bis zum Blatt.
Netzwerkmodell
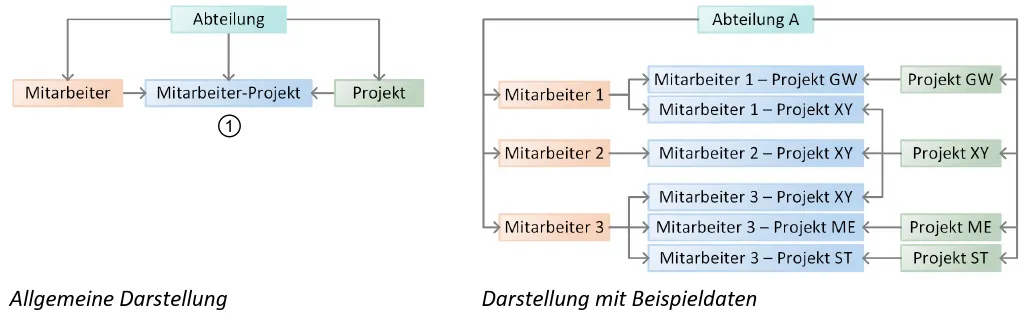
Abschnitt betitelt „Netzwerkmodell“Das Netzmodell erweitert das hierarchische Denken: Datensätze (Records) werden in gleichartige Gruppen (Recordsets) gespeichert und über feste Beziehungen verknüpft. Diese Beziehungen heißen Sets. Jedes Set verbindet genau einen Owner (Besitzer) mit vielen Membern (Mitgliedern). Ein und derselbe Record kann aber zu mehreren Sets gehören - dadurch entsteht kein Baum, sondern ein gerichteter Graph (ein Netzwerk).
Grundprinzip (Owner-Member-Beziehungen):
-
Ein Record kann mehrere “Eltern” haben. Weil ein Record in mehreren Sets Member sein darf, sind z. B. Viele-zu-Viele-Beziehungen möglich (oft über einen kleinen Zwischen-Record).
-
Ein Set ist 1:n: Ein Owner, viele Member. Ein Record kann zugleich Owner in einem Set und Member in anderen Sets sein.
-
Keine feste Wurzel: Es gibt nicht “den” Root. Man wählt einen Start-Record und folgt dann den Links über Sets.
-
Bedeutung durch Verknüpfungen: Was ein Datensatz “bedeutet”, ergibt sich aus seinen Beziehungen im Netzwerk, nicht aus einem einzigen Pfad.
Typische Nutzung & Zugriff:
- Navigation statt Abfragesprache: Man bewegt sich schrittweise (“folgt den Zeigern”) vom Start-Record zu verknüpften Records.
Relationales Modell
Abschnitt betitelt „Relationales Modell“Relationale Datenbanken speichern Daten in Tabellen (mathematisch: Relationen). Relationale Datenbanken sind heute der am weitesten verbreitete Typ von Datenbanksystemen. Die mathematischen Grundlagen von relationalen Datenbanken wurden in den 1970er Jahren von Edgar F. Codd entwickelt. Im Gegensatz zu hierarchische Datenbanken und dem Netzmodell bilden mathematische Überlegungen die Basis für das relationale Modell.
Zeilen heißen Tupel (Datensätze), Spalten Attribute (Felder). Tabellen können über Beziehungen miteinander verknüpft werden - so entsteht ein verständliches, gut auswertbares Datenmodell.
Grundprinzipien:
-
Entitäten & Tabellen: Jede Tabelle beschreibt einen Objekttyp (z. B. Schüler, Kurs, Bestellung).
-
Primärschlüssel: Jede Zeile (Datensatz, Tupel, Record) hat einen eindeutigen Schlüssel (z. B. id), der sie sicher identifiziert.
-
Fremdschlüssel: Beziehungen zwischen Tabellen werden über Verweise hergestellt (Fremdschlüssel).
Beziehungsarten:
-
1:1 (ein Datensatz zu genau einem anderen)
-
1:n (ein Datensatz zu vielen)
-
n:m (viele zu vielen) - umgesetzt über eine Zwischentabelle.
Integrität & Regeln: Constraints (z. B. NOT NULL, UNIQUE, CHECK) und referentielle Integrität sorgen für korrekte, konsistente Daten. Versuche, diese Regeln zu brechen weist die Datenbank zurück.
Normalisierung: Aufteilung in sinnvolle Tabellen (1NF, 2NF, 3NF …) reduziert Redundanz und Anomalien. D.h. man kann überprüfen, wie anfällig eine Datenbank für Inkonsistenzen ist und diese gegebenenfalls beheben.
Modellierung & Darstellung:
- ERM (Entity-Relationship-Modell): Entitäten (=Tabellen) und ihre Beziehungen werden grafisch mit Linien und Kardinalitäten (1, n, m) gezeigt.
Arbeiten mit Daten:
-
SQL ist der Standard (es gab in der Vergangenheit noch einige andere Sprachen, die sich aber nicht durchsetzen konnten):
-
DDL (engl. Data Definition Language - Struktur anlegen/ändern),
-
DML (engl. Data Manipulation Language - Daten einfügen/ändern/löschen),
-
DQL (engl. Data Query Language - Daten abfragen, z. B. SELECT mit JOINs).
-
Ad-hoc-Abfragen und Views erlauben vielfältige Auswertungen.

Spaltenorientierte Datenbanken
Abschnitt betitelt „Spaltenorientierte Datenbanken“Auf Basis von relationalem Modell. Hier werden allerdings die Daten spaltenweise statt zeilenweise gespeichert. Das macht Aggregation (SUM, AVG, COUNT) und Scans über wenige Spalten extrem schnell und spart dank starker Kompression viel Speicher. Typisch für Analytics/OLAP, Data Warehouses und Log-Auswertungen.
Weniger geeignet sind sie für sehr häufige Einzel-Updates kompletter Zeilen (klassisches OLTP).
Dokumentorientierte Datenbanken
Abschnitt betitelt „Dokumentorientierte Datenbanken“Daten liegen als Dokumente (meist JSON/BSON) vor - flexibel, ohne strenges Schema. Verschachtelte Strukturen passen gut zu Web-Objekten (z. B. Bestellung mit Positionen). Man sucht über Felder/Indizes und speichert oft “alles, was zusammengehört”, in einem Dokument. Gut, wenn man vorab nicht genau weiß, welche Felder nötig sind (z. B. User-Profile, Content-Management).
Stärken: Schnelle Entwicklung, flexible Modelle, gute horizontale Skalierung. Trade-offs: Joins sind unüblich (man embeddet), Transaktionen über mehrere Dokumente sind je nach System eingeschränkt. Typisch: MongoDB, CouchDB.
Objektorientierte Datenbanken
Abschnitt betitelt „Objektorientierte Datenbanken“Sie speichern direkt Objekte mit Attributen und Methoden - samt Vererbung und Referenzen (Zeiger). Damit entfällt das “Mapping” zwischen Objektwelt und Tabellen. Objekte bleiben identisch und kapseln ihr Verhalten.
Vorteile: Kein Impedance Mismatch, natürlich für komplexe Modelle (CAD, Simulation, wissenschaftliche Daten). Nachteile: Wenig Standardisierung, schwächere Ad-hoc-Abfragen als SQL, geringere Verbreitung. Beispiele: ObjectDB u. ä.
Objektrelationale Datenbanken
Abschnitt betitelt „Objektrelationale Datenbanken“Kern ist relational (Tabellen, SQL), ergänzt um objektnahe Features: benutzerdefinierte Datentypen, Arrays/JSON, Tabelle-Vererbung, Funktionen/Prozeduren nahe an den Daten. Man bleibt bei SQL, kann aber komplexe Strukturen sauber modellieren.
Gut, wenn man relationales Denken plus reichere Datentypen braucht (z. B. Geodaten, JSON). Vorteile: starke Transaktionen, Integrität + Flexibilität. Nachteile: Komplexer, teils vendor-spezifisch. Typisch: PostgreSQL, Oracle.
NoSQL-Datenbanken
Abschnitt betitelt „NoSQL-Datenbanken“Mit dem explosionsartigen Wachstum des Internets stiegen auch die Datenmengen und die Zahl gleichzeitiger Zugriffe in einzelnen Datenbanken stark an. Klassische relationale Systeme geraten dabei an Grenzen - etwa bei extrem vielen Lese-/Schreibzugriffen oder häufigen Datenänderungen. Zusätzlich sind sie stark schemafixiert: Änderungen an großen Schemata sind aufwendig und können riskant sein. NoSQL-Datenbanken lösen diese Probleme, indem sie flexible (schemaarme/-freie) Modelle anbieten und von Anfang an auf Verteilung über viele Server setzen (Sharding, Replikation), inklusive bewusster Redundanz für Ausfallsicherheit und Skalierung.
Vorreiter dieser Entwicklung waren u. a. Google, Amazon, eBay und Facebook. Die Bedeutung von NoSQL zeigt sich auch daran, dass verbreitete relationale Systeme wie MariaDB und PostgreSQL heute NoSQL-Funktionen mitbringen (z. B. JSON-Speicherung, Key/Value-Features). Der Begriff “NoSQL” tauchte Ende der 1990er als Name einer kleinen Datenbank zunächst im Sinn von “nicht SQL” auf. Später verstand man ihn breiter als “not only SQL”: Es geht nicht gegen SQL, sondern um alternative Datenmodelle neben dem Relationalen - teils mit Konzepten, die bereits früher diskutiert wurden (bsp. dokumentenorientierte oder spaltenorientierte Ansätze).
Dokumentenorientierte Datenbanken
Abschnitt betitelt „Dokumentenorientierte Datenbanken“Speichern Daten als Dokumente (z. B. JSON). Gut für natürlich verschachtelte Strukturen und schnelle Entwicklung ohne starres Schema.
Graphen-Datenbanken
Abschnitt betitelt „Graphen-Datenbanken“Ideal, wenn viele Querverbindungen zwischen Daten verwaltet werden müssen (z. B. “Wer folgt wem?” in sozialen Netzen). Daten sind Knoten, Beziehungen sind Kanten.
Key/Value-Datenbanken:
Abschnitt betitelt „Key/Value-Datenbanken:“Sehr einfaches Schema: Ein Key (beliebige Zeichenkette) verweist auf einen Value (Einzelwert, Liste oder Set). Wichtige Unterscheidung: Speicherort - im RAM (sehr schnell) oder auf externen Medien. Systeme dieser Gruppe werden häufig für Caching, Sitzungsdaten oder große, verteilte Workloads eingesetzt.
Lernergebnisse: Was Sie nach diesem Kapitel können sollten
Abschnitt betitelt „Lernergebnisse: Was Sie nach diesem Kapitel können sollten“Nach Abschluss dieses Kapitels sollten Schülerinnen und Schüler in der Lage sein:
- Nennen: die zentralen Bestandteile eines Datenbanksystems (DBMS, Datenbank, Anwendungen) sowie wichtige Stationen der Datenbankgeschichte nennen.
- Beschreiben: die Entwicklung von der klassischen Dateiverwaltung hin zu Datenbanksystemen beschreiben.
- Erklären: die wesentlichen Eigenschaften und Aufgaben eines DBMS (z. B. Datenunabhängigkeit, Mehrbenutzerbetrieb, Konsistenz) erklären.
- Vergleichen: die Datenhaltung in Dateisystemen mit jener in Datenbanksystemen gegenüberstellen.
- Beurteilen: beurteilen, für welche Anwendungsfälle der Einsatz eines Datenbanksystems sinnvoll ist.